
DRL Value-based Methods
Updated:
from IPython.display import Image
Image(filename='./images/2-0-0-0_opening.jpg')

Learning Plan
Lesson 2-1: Neural Networks (Optional)
you are expected to know how neural networks train through backpropagation.
Lesson 2-2: Convolutional Neural Networks (Optional)
If you’d like to review convolutional neural networks, check out this lesson in the extracurricular content.
Lesson 2-3: Deep Learning with PyTorch (Optional)
We will use PyTorch throughout this program. If the PyTorch framework is new to you, please take a look at our introductory lesson in the extracurricular content.
Lesson 2-4: Deep Q-Networks
In this lesson, you will learn all of the details behind the Deep Q-Networks (DQN) algorithm.
Lesson 2-5: Deep RL in Robotics (Optional)
Learn about how to use the Deep Q-Learning algorithm with real-world robotics from experts at NVIDIA’s Deep Learning Institute.
Optional Resorces
- Read this [scientific article] { https://www.cs.swarthmore.edu/~meeden/cs63/s15/nature15a.pdf } that describes Deep Q-Networks.
- Read the [research paper] { https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf } that first introduced the Deep Q-Learning algorithm.
- Learn more about Deep Q-Learning and Google DeepMind by watching this [video] { https://www.youtube.com/watch?v=xN1d3qHMIEQ }.
Then, in the lesson Deep RL for Robotics, you will learn how to use Deep Q-Learning to train a robotic agent to drive in a [Gazebo] { http://gazebosim.org/ } environment.
from IPython.display import Image
Image(filename='./images/2-0-0-1_deep_rl_in_robotics_using_DQN.gif')
<IPython.core.display.Image object>
Deep RL for Robotics - Optional Resorces
- Read [this article] { https://www.technologyreview.com/s/601045/this-factory-robot-learns-a-new-job-overnight/ } if you’d like to learn more about how the Japanese robot company Fanuc uses deep RL to learn new tasks.
- [This robot] { https://www.cnet.com/news/robot-learns-via-trial-and-error-like-a-human/ } at UC Berkeley also uses deep RL to learn new skills.
- Learn how [Amazon is using deep RL] { https://medium.com/@teamrework/deep-learning-in-production-warehousing-with-amazon-robotics-571e69fea721 } to make their warehouses more efficient.
Lesson 2-4: Deep Q-Networks
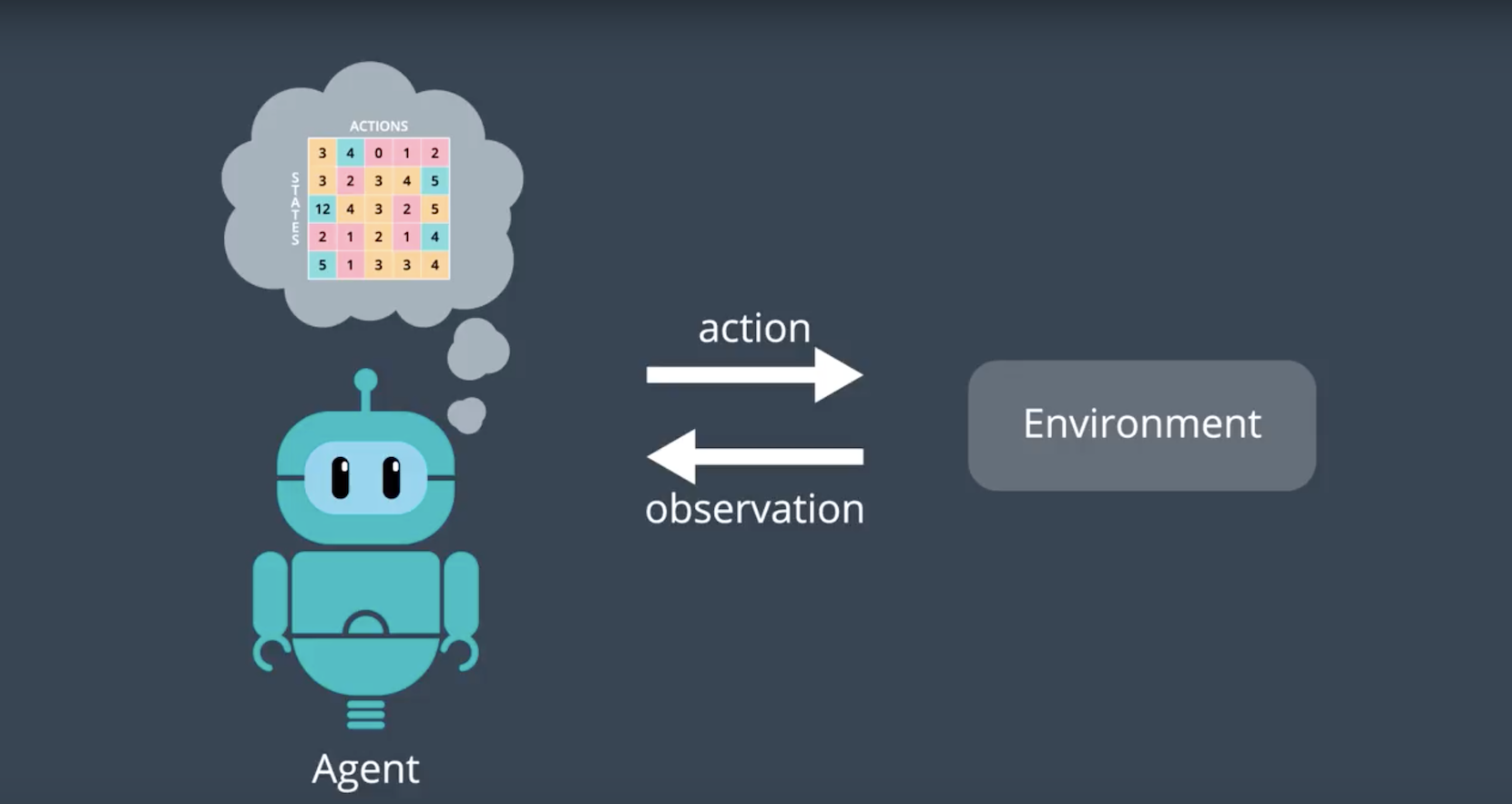
So far, you’ve solved many of your own reinforcement learning problems, using solution methods that represent the action values in a small table. Earlier in the nanodegree, we referred to this table as a Q-table.
In the lesson below, It will be introduced you to the idea of using neural networks to expand the size of the problems that we can solve with reinforcement learning. This context is useful preparation for exploring the details behind the Deep Q-Learning algorithm later in this lesson.
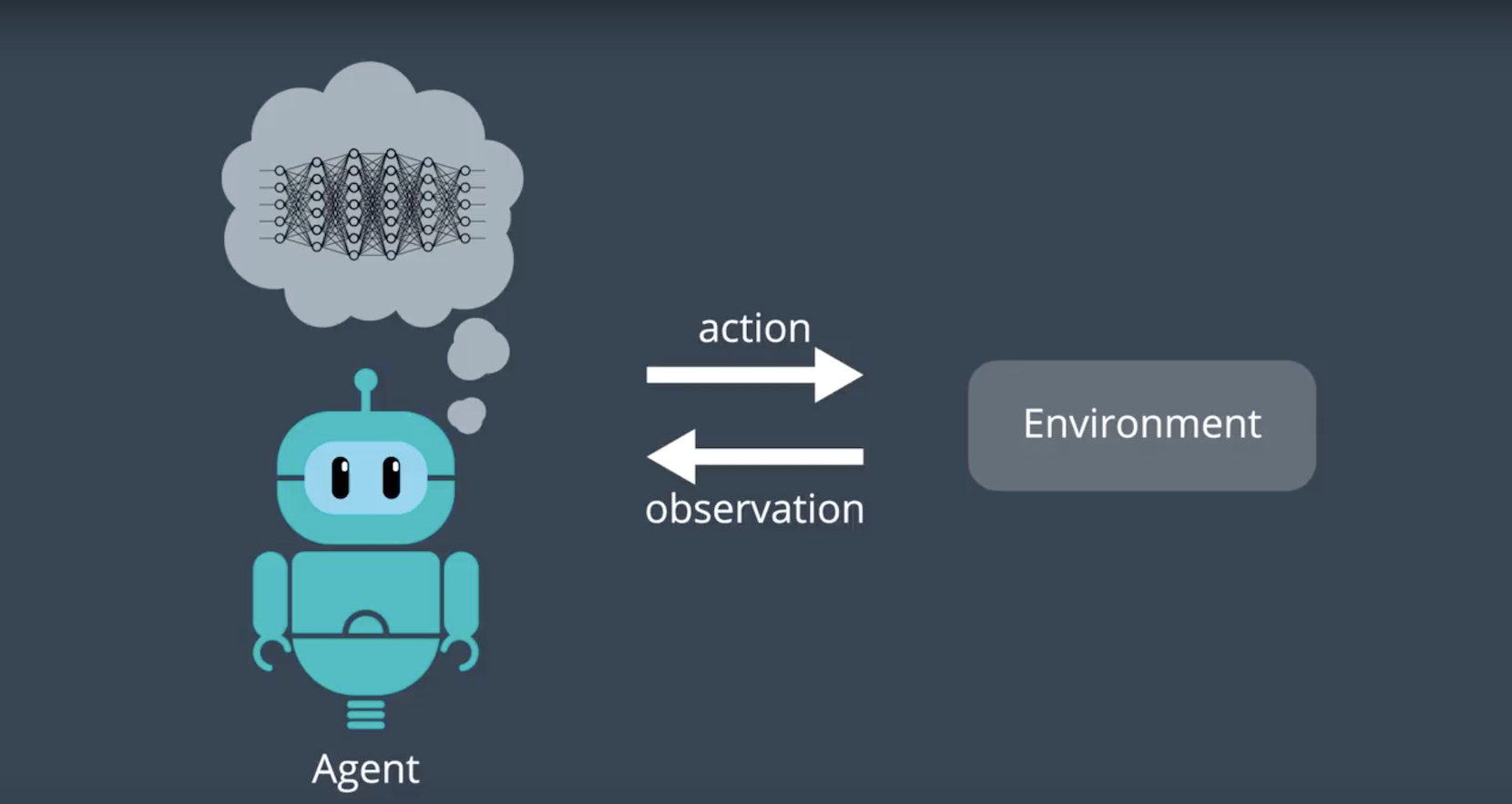
2-4-1 : From RL to Deep RL
from IPython.display import Image
Image(filename='./images/2-4-1-1_from_rl_to_deep_rl.png')
from IPython.display import Image
Image(filename='./images/2-4-1-2_from_rl_to_deep_rl.png')
from IPython.display import Image
Image(filename='./images/2-4-1-3_from_rl_to_deep_rl.png')
from IPython.display import Image
Image(filename='./images/2-4-1-4_from_rl_to_deep_rl.png')
from IPython.display import Image
Image(filename='./images/2-4-1-5_from_rl_to_deep_rl.png')
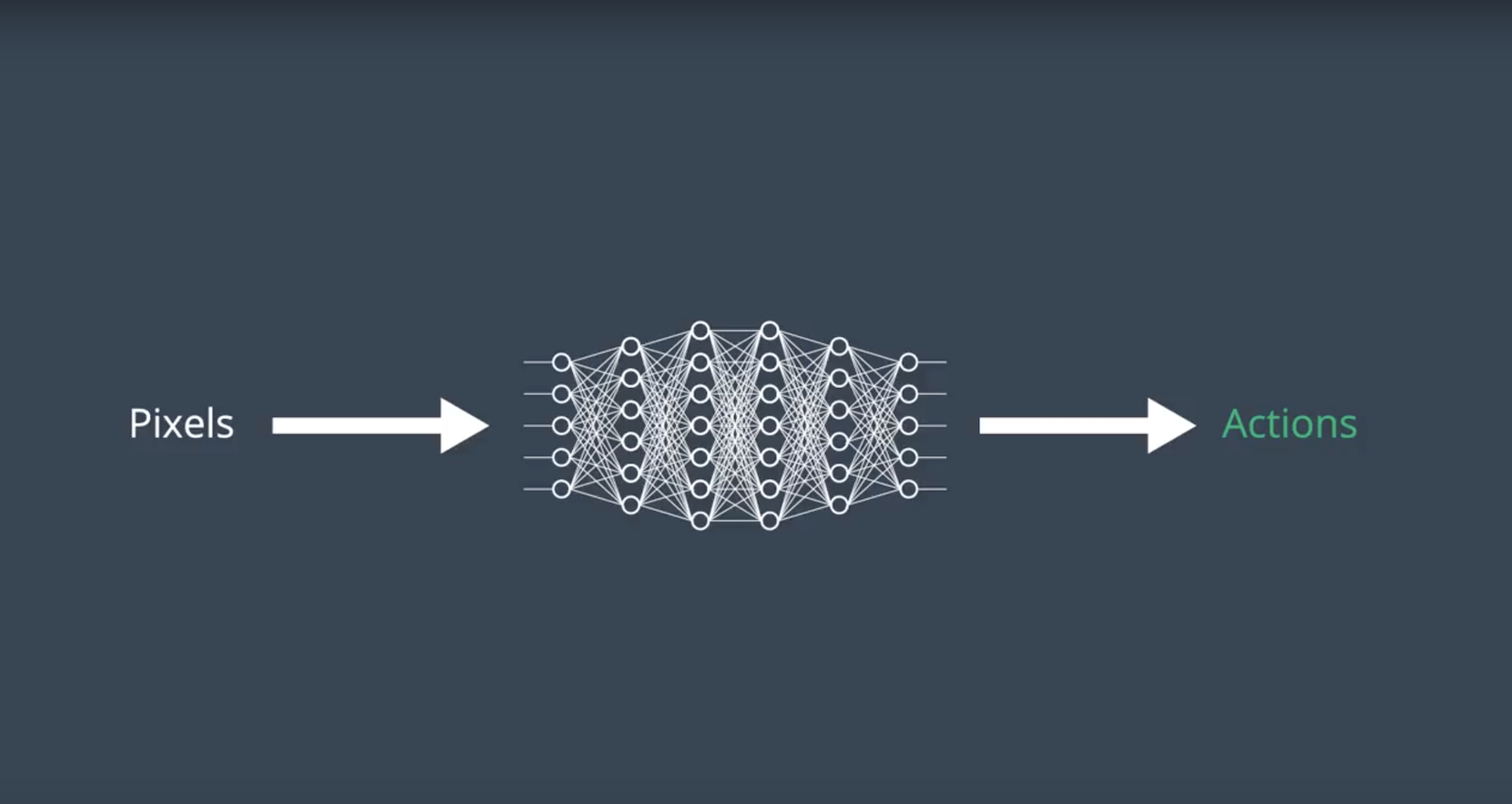
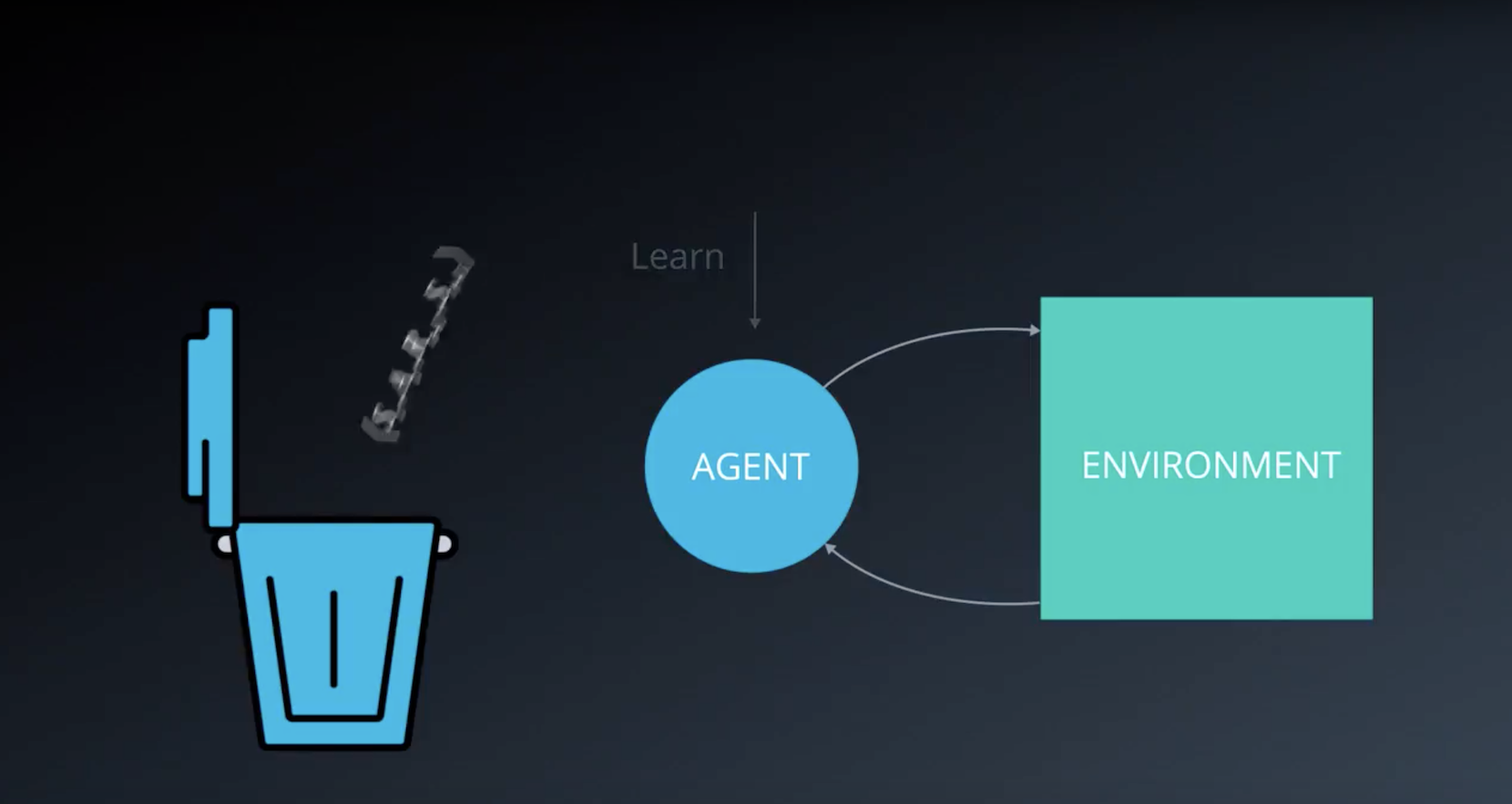
Stabilizing Deep Reinforcement Learning
As you’ll learn in this lesson, the Deep Q-Learning algorithm represents the optimal action-value function q∗ as a neural network (instead of a table).
Unfortunately, reinforcement learning is notoriously unstable when neural networks are used to represent the action values. In this lesson, you’ll learn all about the Deep Q-Le arning algorithm, which addressed these instabilities by using two key features:
* Experience Replay
* Fixed Q-Targets
Additional References
- Riedmiller, Martin. “Neural fitted Q iteration–first experiences with a data efficient neural reinforcement learning method.” European Conference on Machine Learning. Springer, Berlin, Heidelberg, 2005. http://ml.informatik.uni-freiburg.de/former/_media/publications/rieecml05.pdf
- Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature518.7540 (2015): 529. http://www.davidqiu.com:8888/research/nature14236.pdf
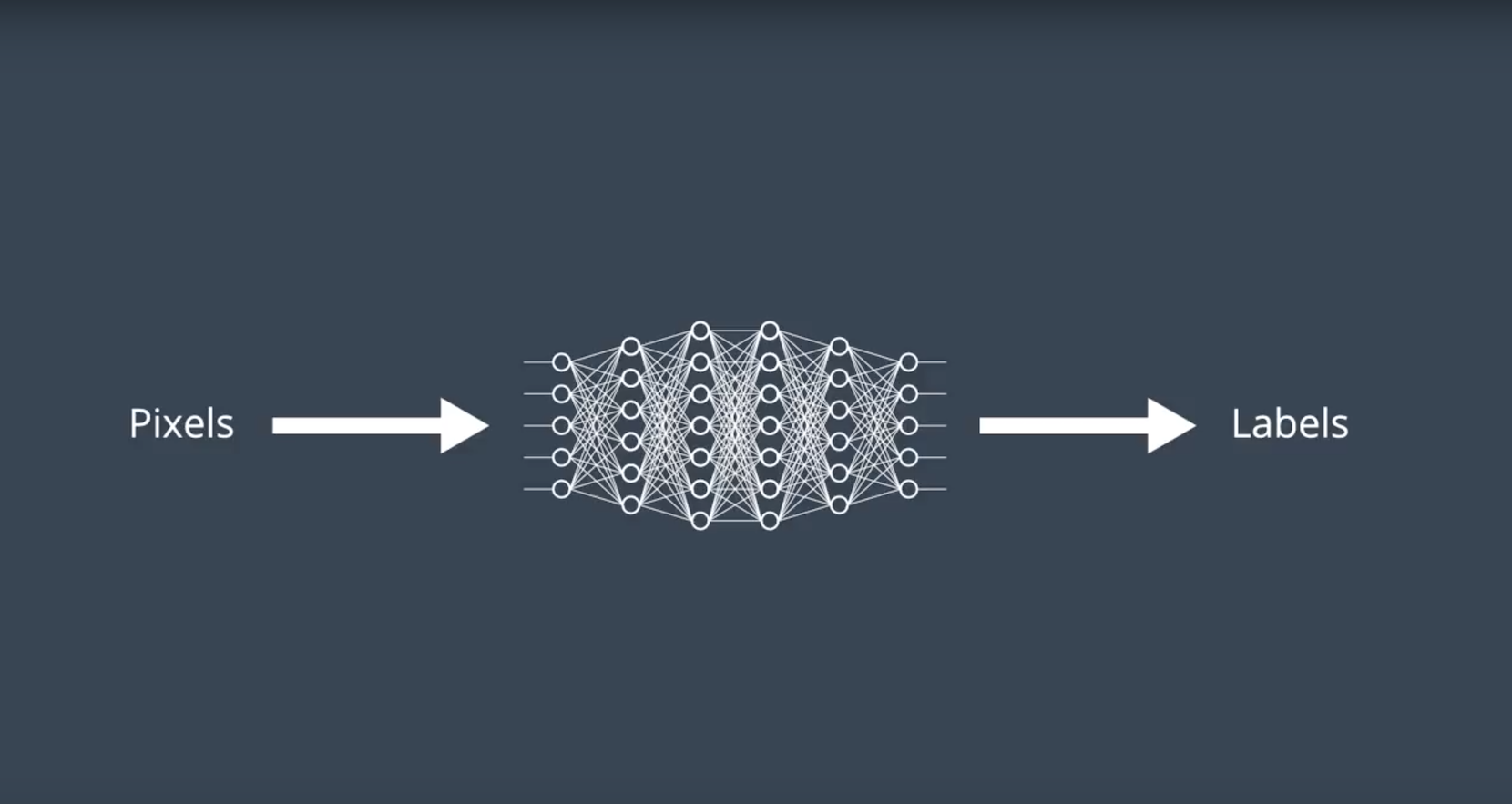
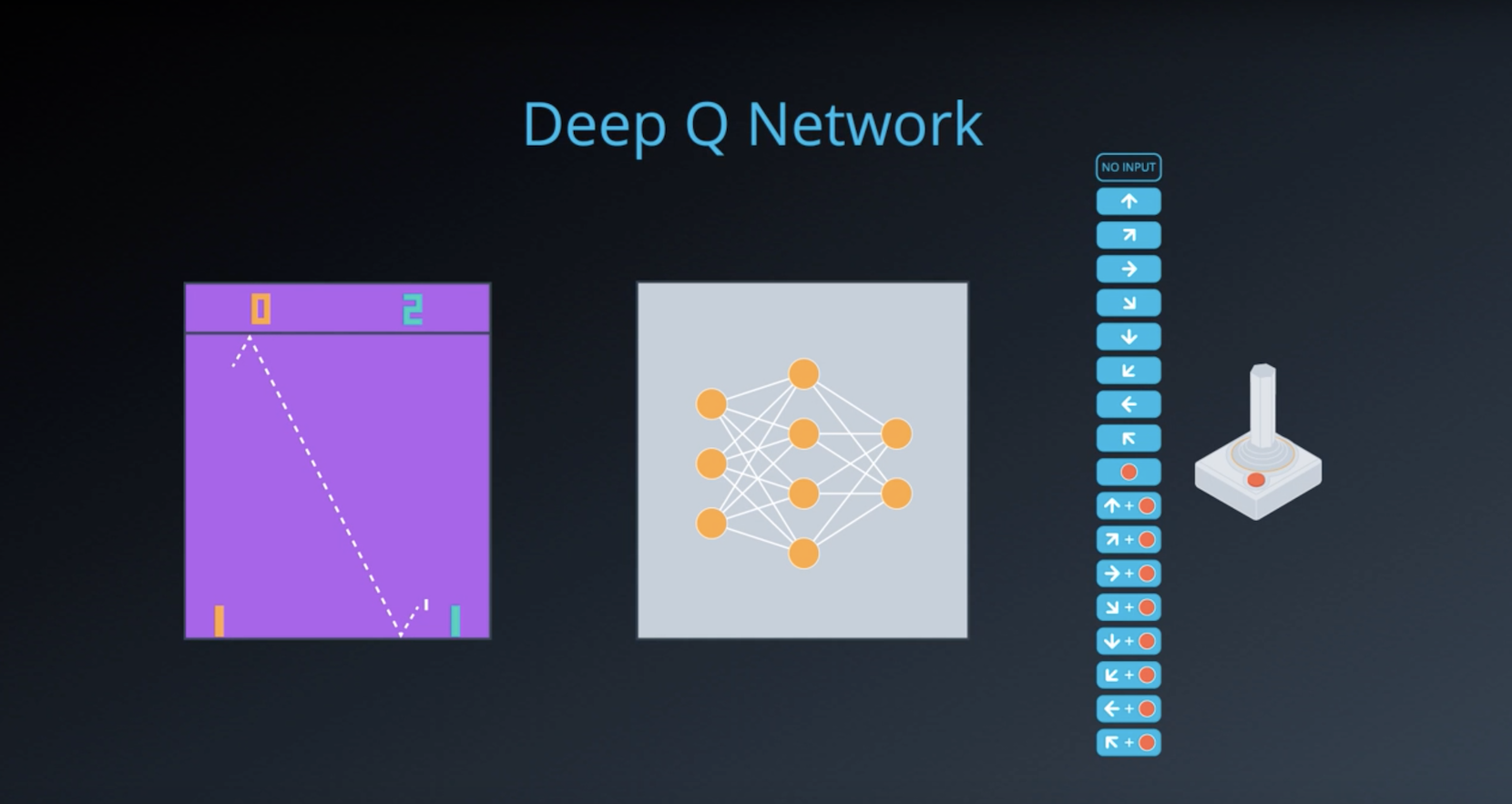
2-4-2 : Deep Q Networks
from IPython.display import Image
Image(filename='./images/2-4-2-1_dqn_function_approximator.png')
from IPython.display import Image
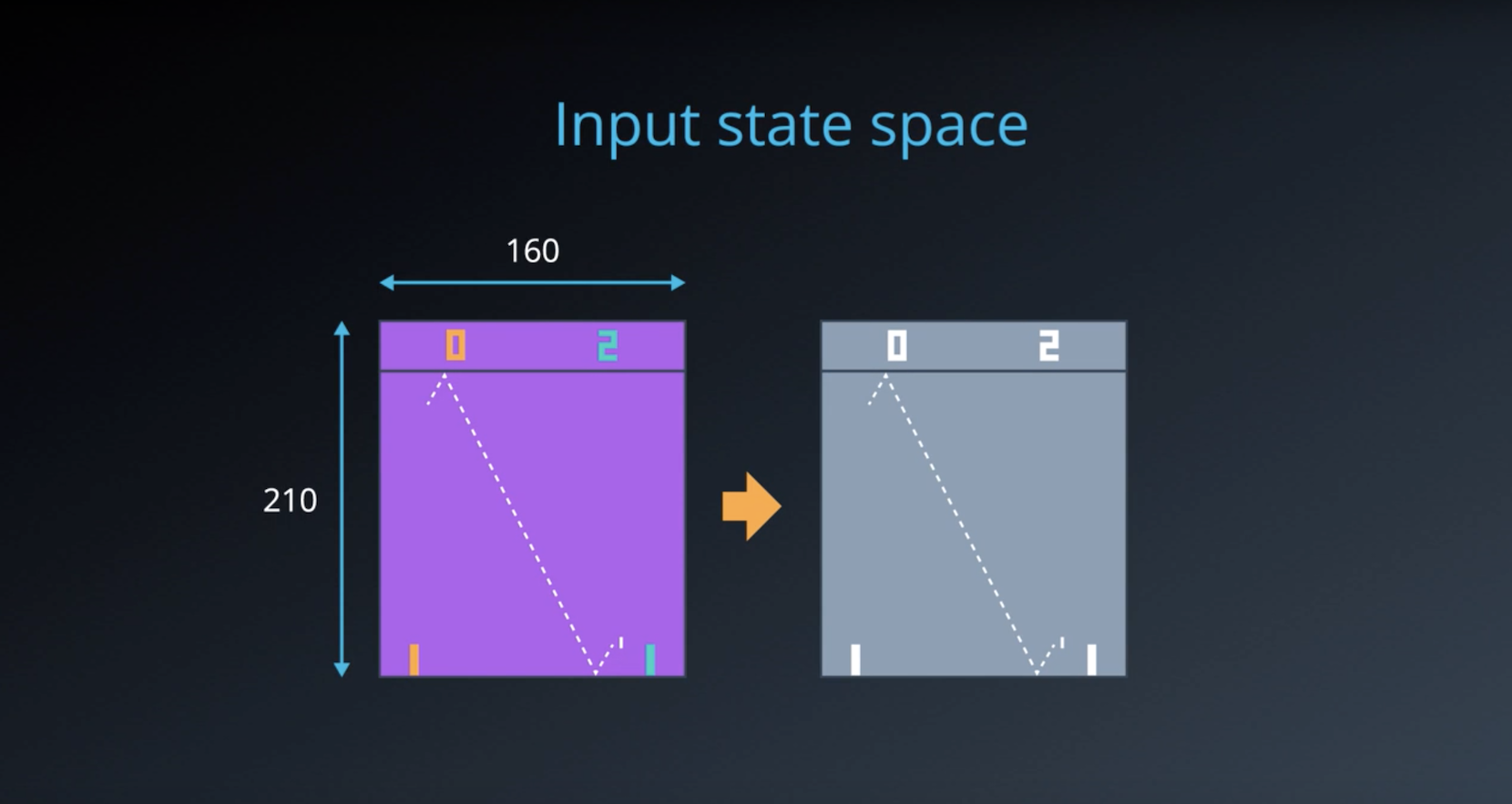
Image(filename='./images/2-4-2-2_dqn_input_state_space.png')
from IPython.display import Image
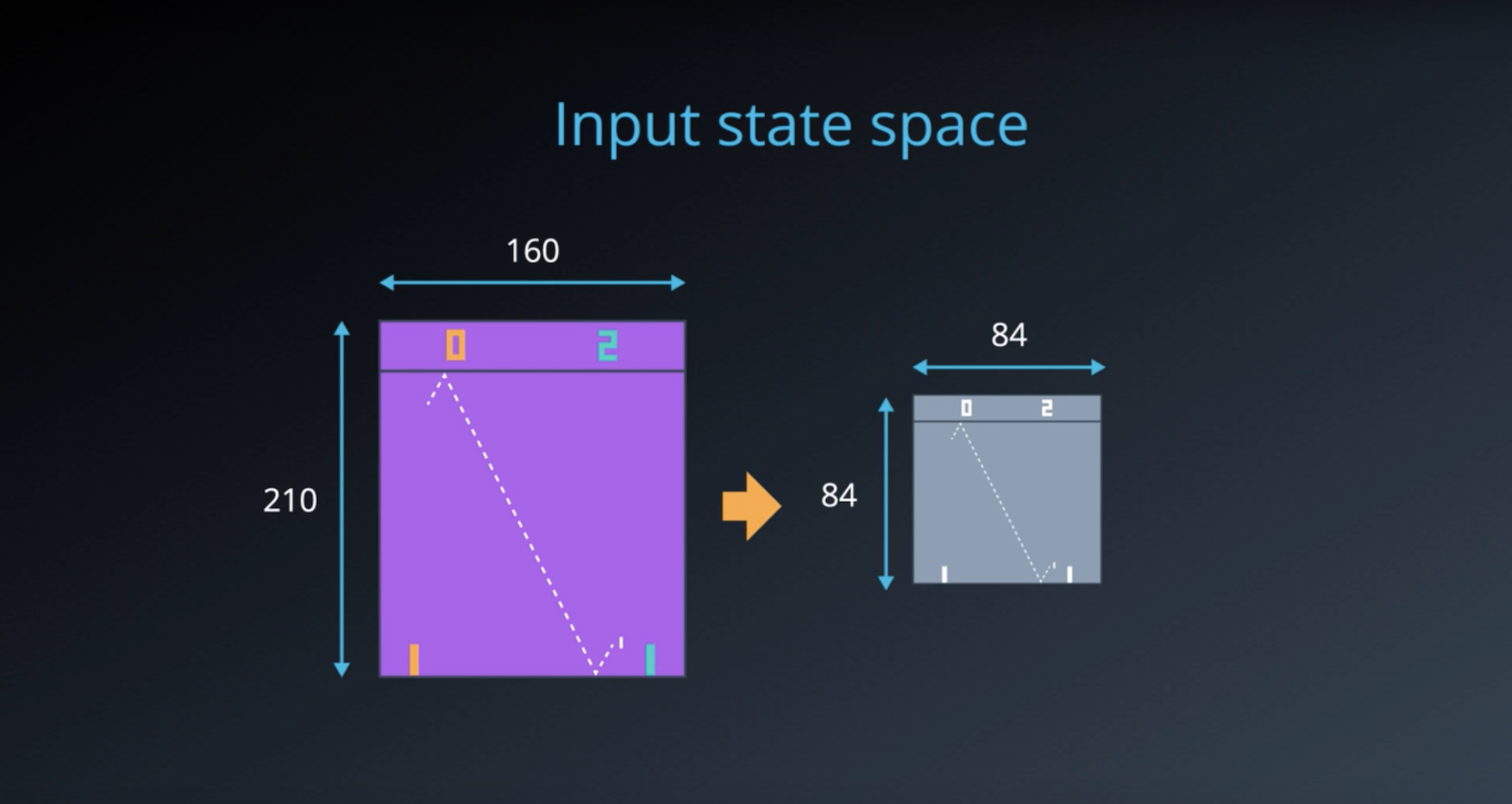
Image(filename='./images/2-4-2-3_dqn_input_state_space_preprocessing.png')
from IPython.display import Image
Image(filename='./images/2-4-2-4_dqn_input_state_space_preprocessing_to_capture_temporal_information.png')
from IPython.display import Image
Image(filename='./images/2-4-2-5_dqn_action_vetor_output.png')
from IPython.display import Image
Image(filename='./images/2-4-2-6_dqn_with_cnn_and_fcn.png')
Quiz
Select all that are true.
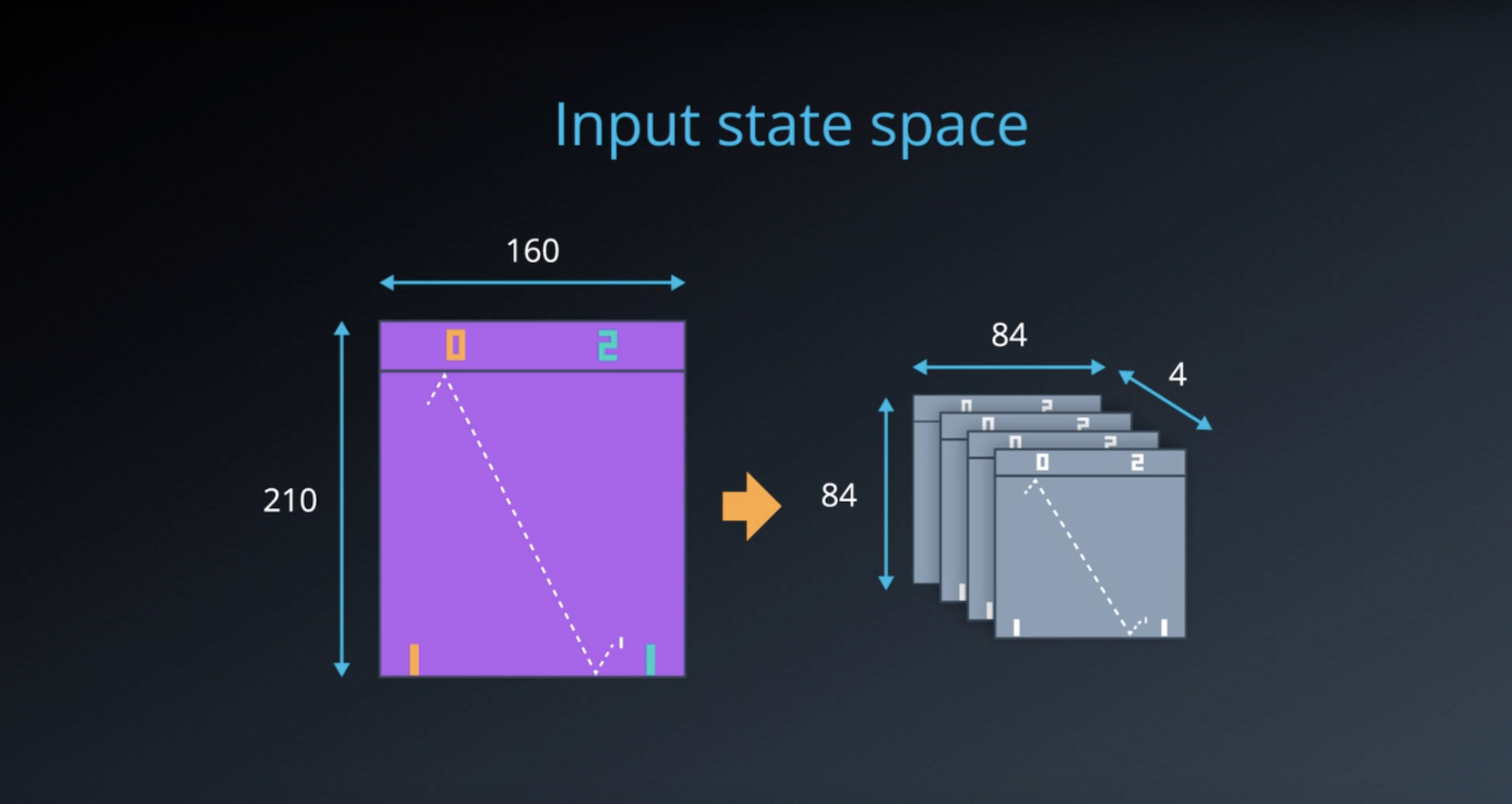
- The Deep Q-Network (DQN) receives the most recent state of the game as input. After some preprocessing, this is the 84x84x1 (grayscale) game screen.
- In order to capture temporal information, a stack of 4 preprocessed frames are used as the state that is passed to the DQN.
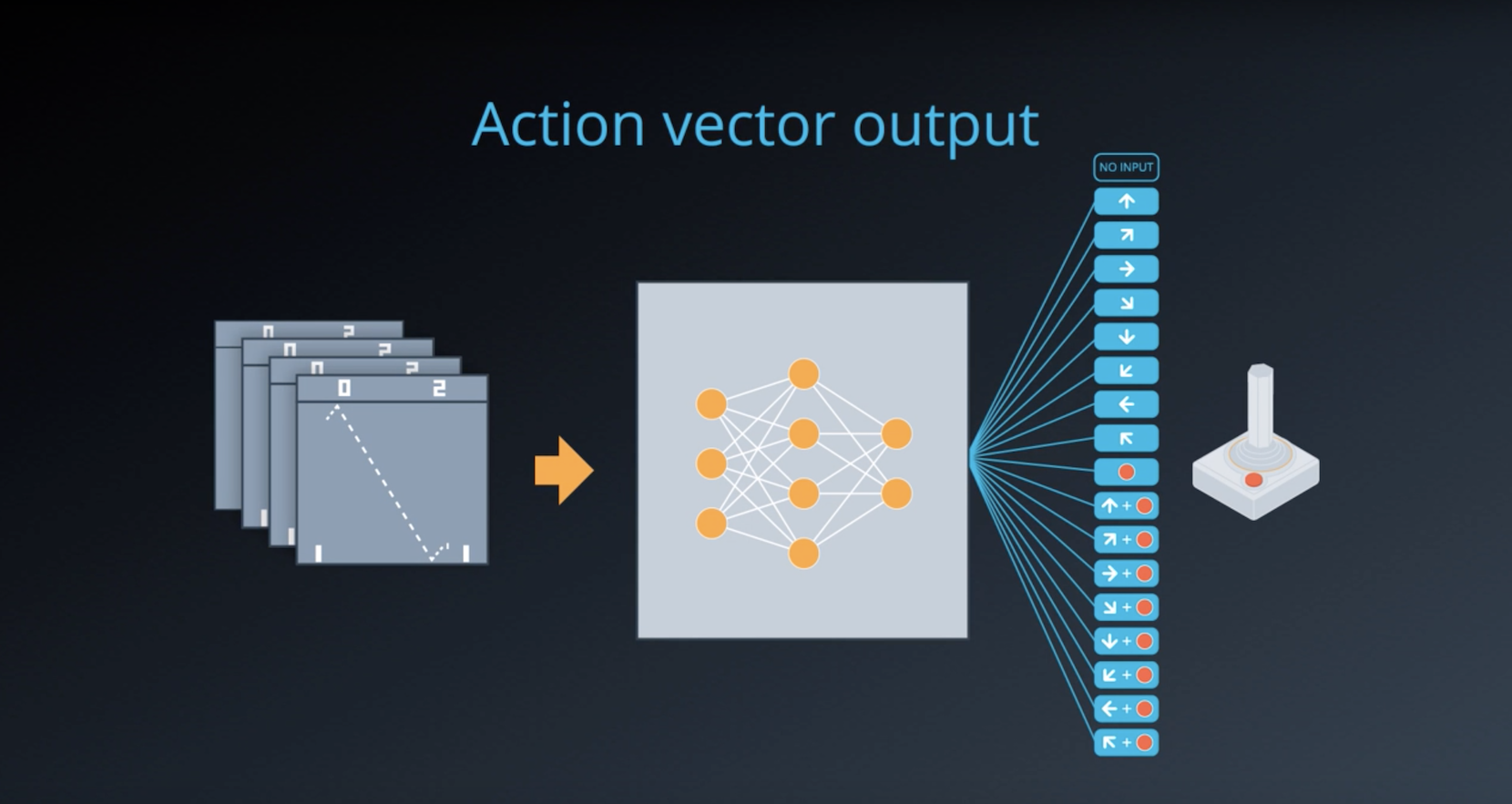
- The DQN takes a state and action as input, and returns the corresponding predicted action value.
- The DQN takes the state as input, and returns the corresponding predicted action values for each possible game action.
- The DQN was provided information about the game of pong - before the agent started learning, the researchers wrote helper functions to ensure the agent always keeps the paddle close to the ball.
- The DQN architecture included a combination of convolutional and recurrent layers. The CNN component captures spatial information in the state, and the RNN component detects temporal patterns.
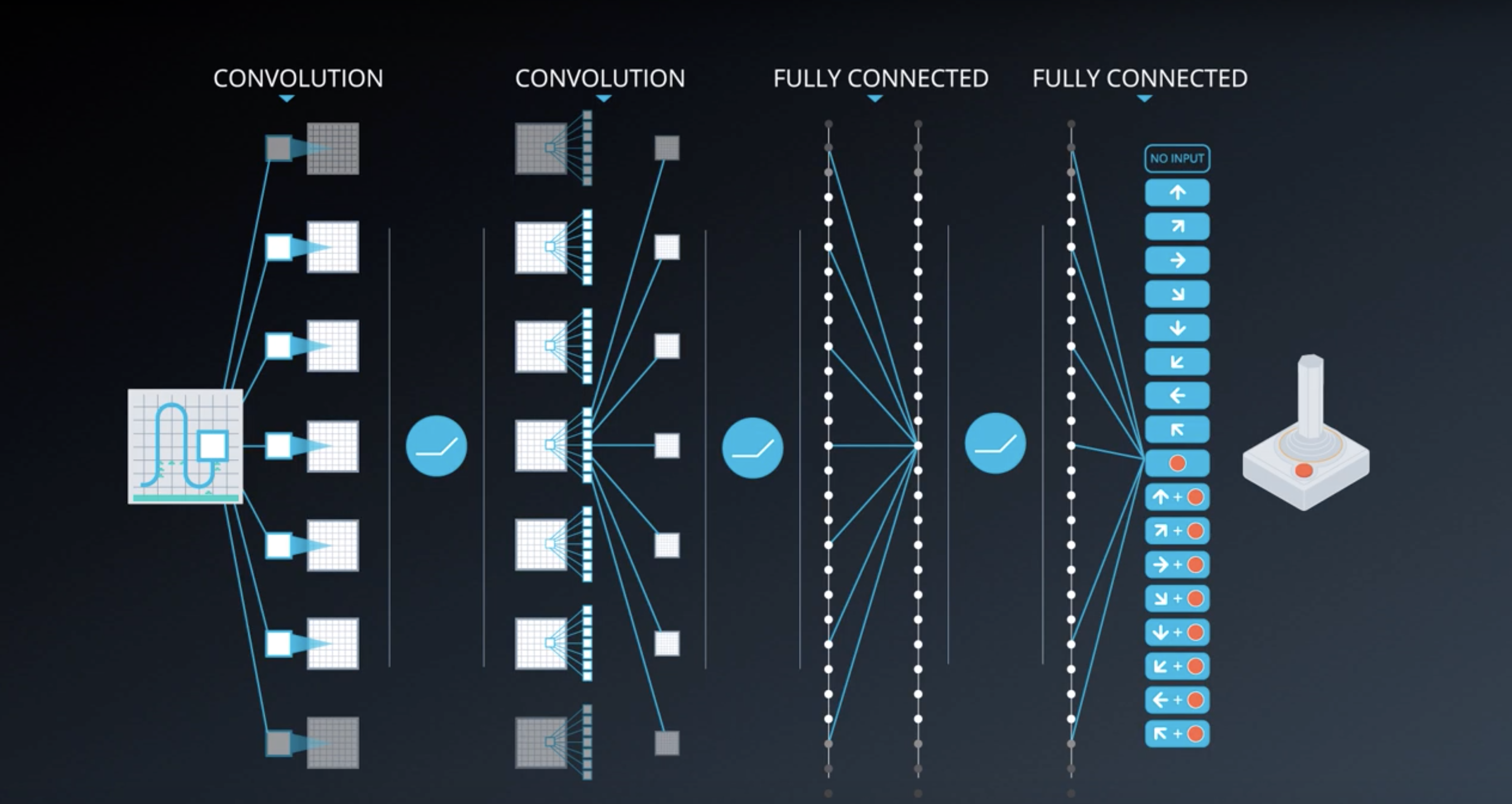
- The DQN architecture is fully convolutional: it has only convolutional layers and no fully-connected layers.
- The DQN architecture is composed of a couple of convolutional layers, followed by a couple of fully connected layers.
- For each Atari game, the DQN was trained from scratch on that game.
- The DQN was trained on data from the first several games, and then with that knowledge (and no additional training), it could beat the remaining Atari games.
2-4-3 : Experience Replay
from IPython.display import Image
Image(filename='./images/2-4-3-1_dqn_experience_replay_step1.png')

from IPython.display import Image
Image(filename='./images/2-4-3-2_dqn_experience_replay_step2.png')
from IPython.display import Image
Image(filename='./images/2-4-3-3_dqn_experience_replay_step3.png')
from IPython.display import Image
Image(filename='./images/2-4-3-4_dqn_experience_replay_step4.png')
from IPython.display import Image
Image(filename='./images/2-4-3-5_dqn_experience_replay_step5.png')
from IPython.display import Image
Image(filename='./images/2-4-3-6_dqn_experience_replay_step6.png')
from IPython.display import Image
Image(filename='./images/2-4-3-7_dqn_experience_replay_step7.png')
from IPython.display import Image
Image(filename='./images/2-4-3-8_dqn_experience_replay_tennis_example_step1.png')

from IPython.display import Image
Image(filename='./images/2-4-3-9_dqn_experience_replay_tennis_example_step2.png')

from IPython.display import Image
Image(filename='./images/2-4-3-10_dqn_experience_replay_tennis_example_step3.png')

from IPython.display import Image
Image(filename='./images/2-4-3-11_dqn_experience_replay_tennis_example_step4.png')

from IPython.display import Image
Image(filename='./images/2-4-3-12_dqn_experience_replay_tennis_example_step5.png')

from IPython.display import Image
Image(filename='./images/2-4-3-13_dqn_experience_replay_tennis_example_step6.png')

from IPython.display import Image
Image(filename='./images/2-4-3-14_dqn_experience_replay_tennis_example_step7.png')

from IPython.display import Image
Image(filename='./images/2-4-3-15_dqn_experience_replay_tennis_example_step8.png')

from IPython.display import Image
Image(filename='./images/2-4-3-16_dqn_experience_replay_tennis_example_step9.png')

from IPython.display import Image
Image(filename='./images/2-4-3-17_dqn_experience_replay_tennis_example_step10.png')

from IPython.display import Image
Image(filename='./images/2-4-3-18_dqn_experience_replay_tennis_example_step11.png')

from IPython.display import Image
Image(filename='./images/2-4-3-19_dqn_experience_replay_means_sl_approach_and prioritized_experience_replay.png')

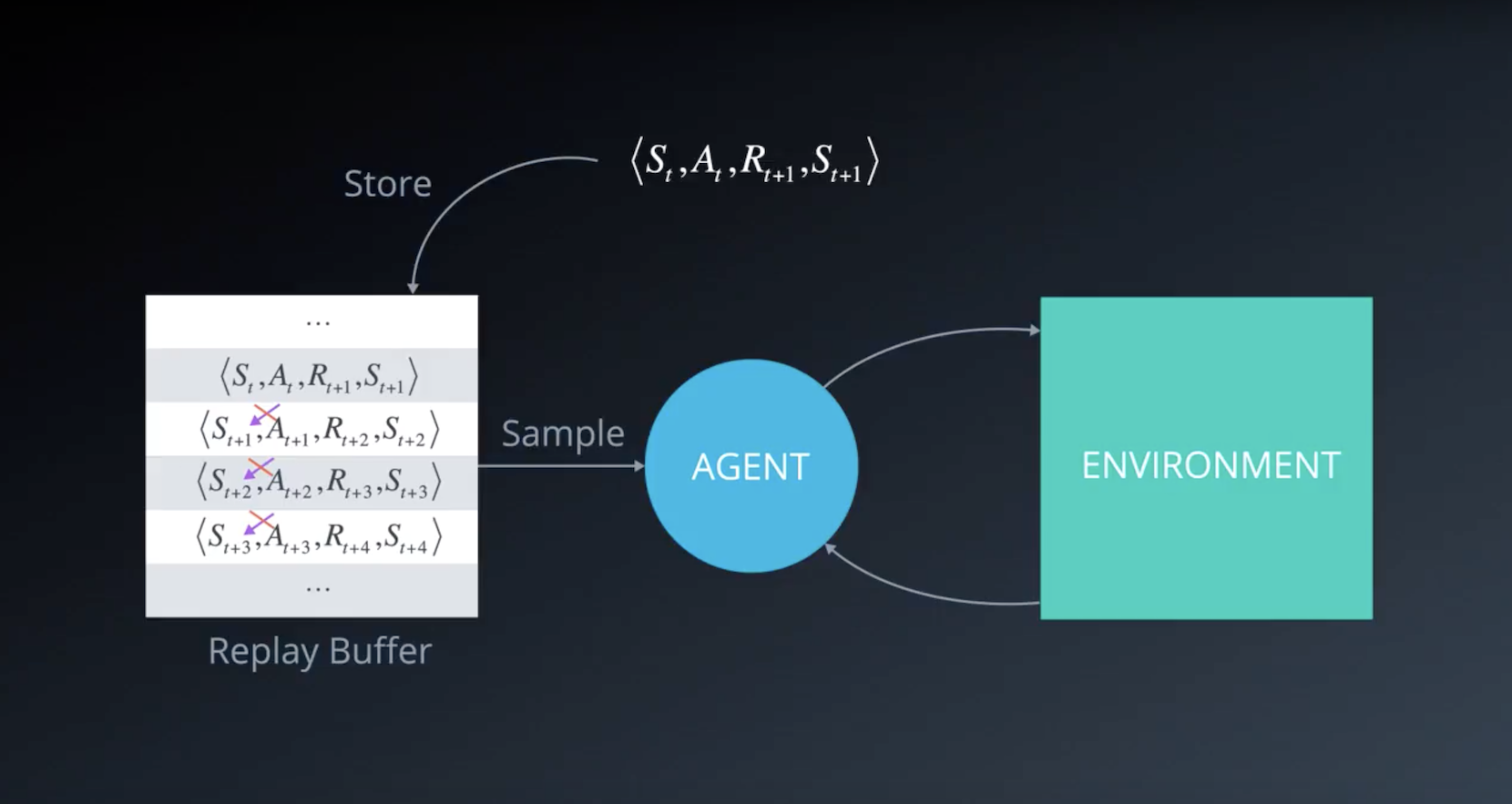
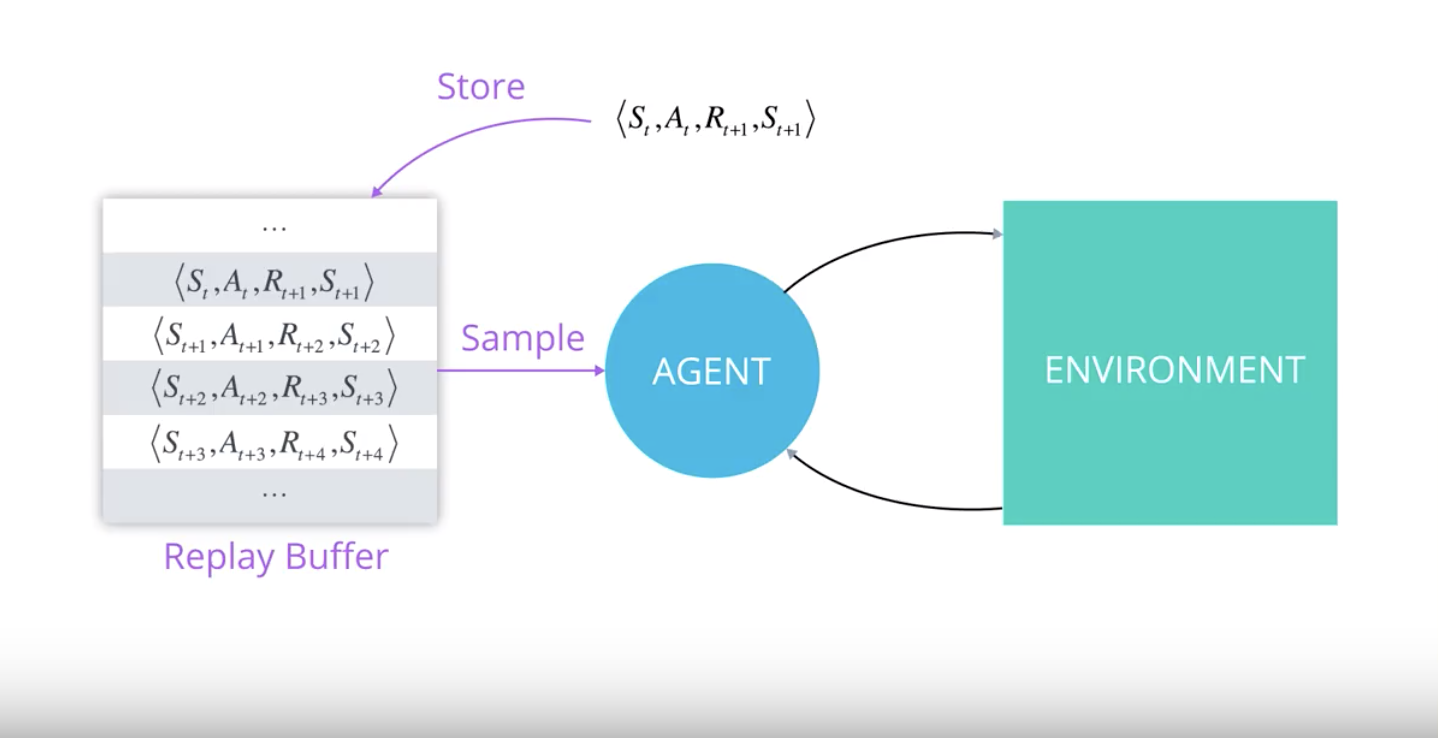
Summary of Experience Replay
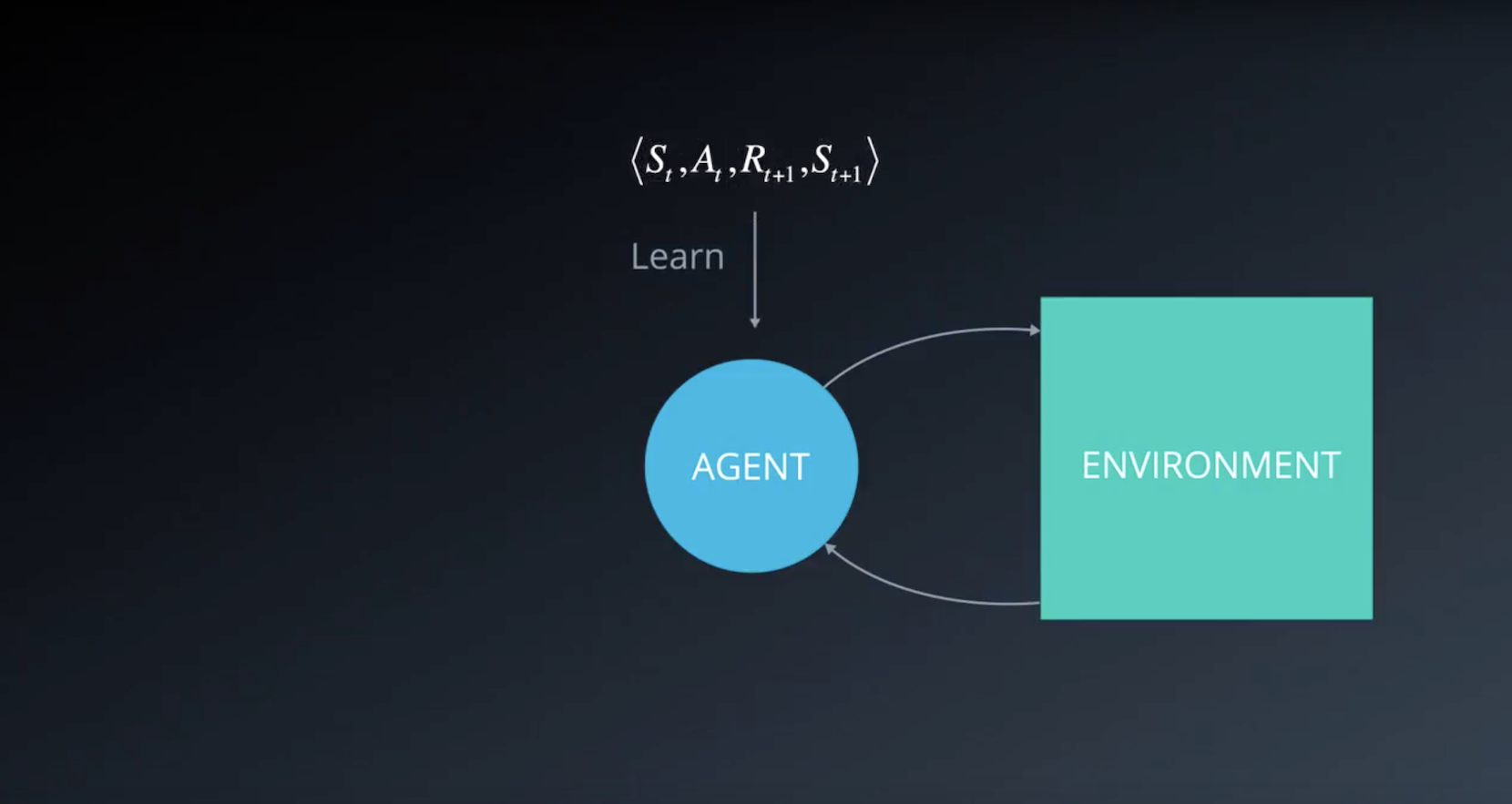
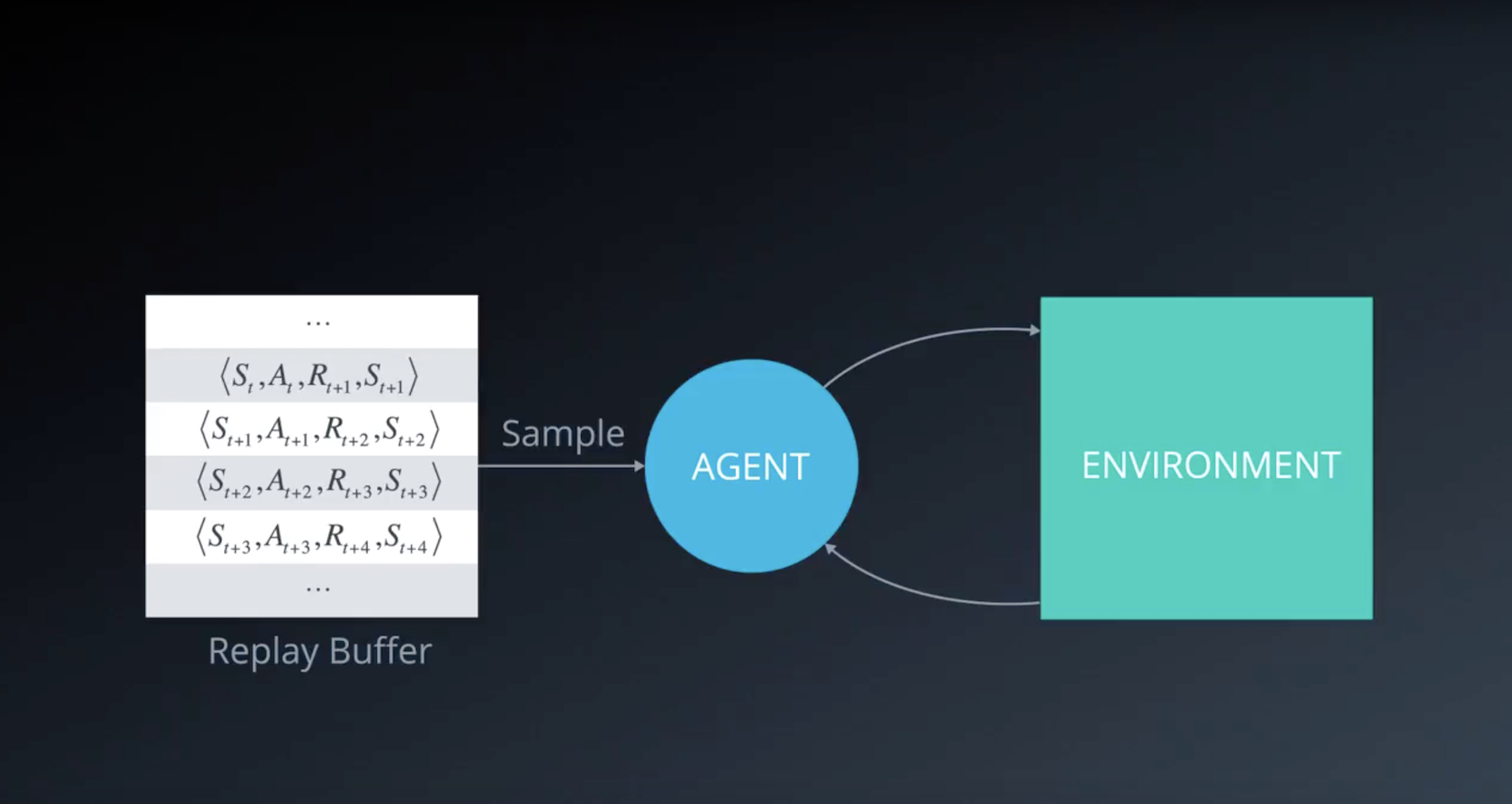
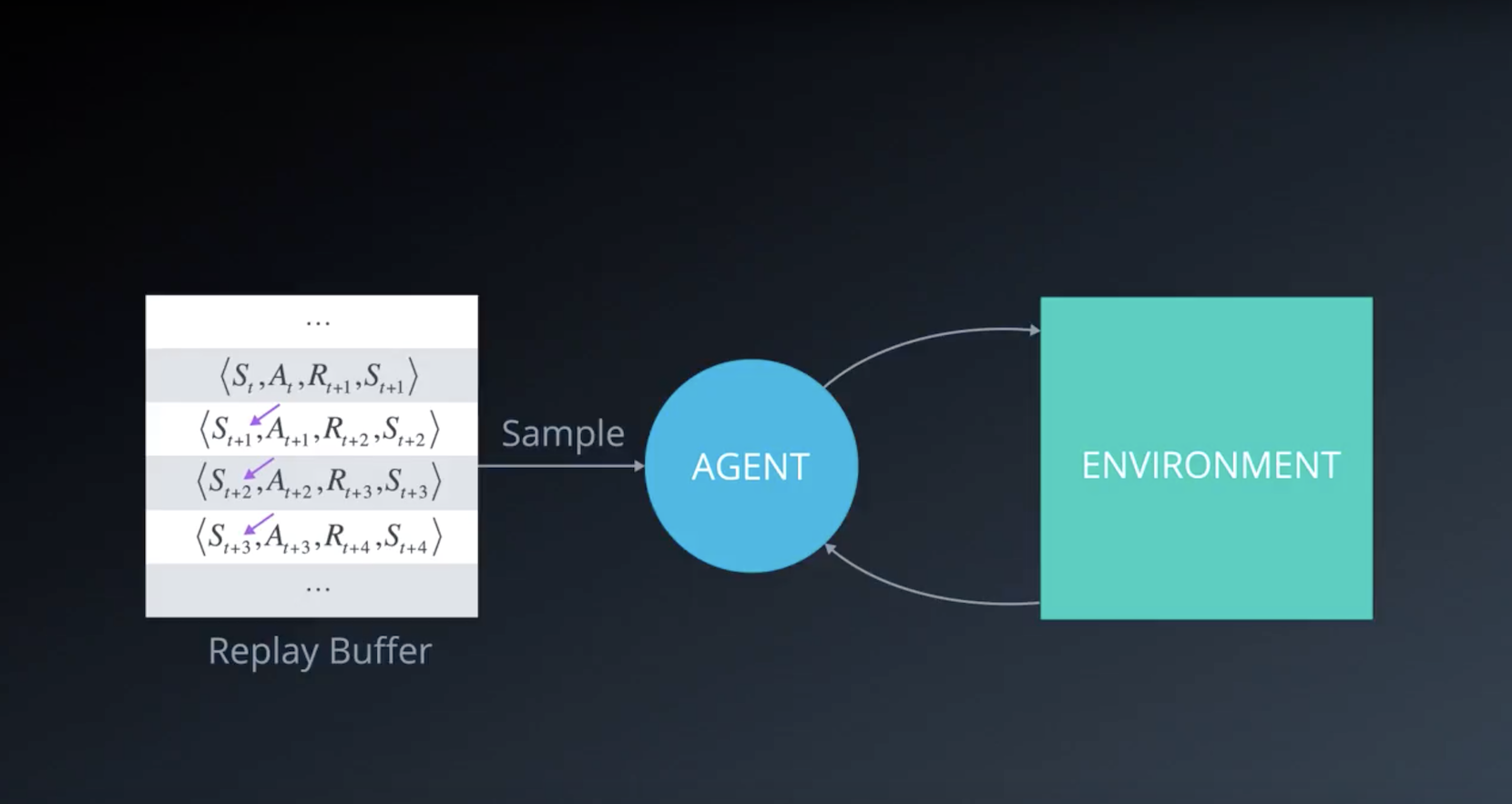
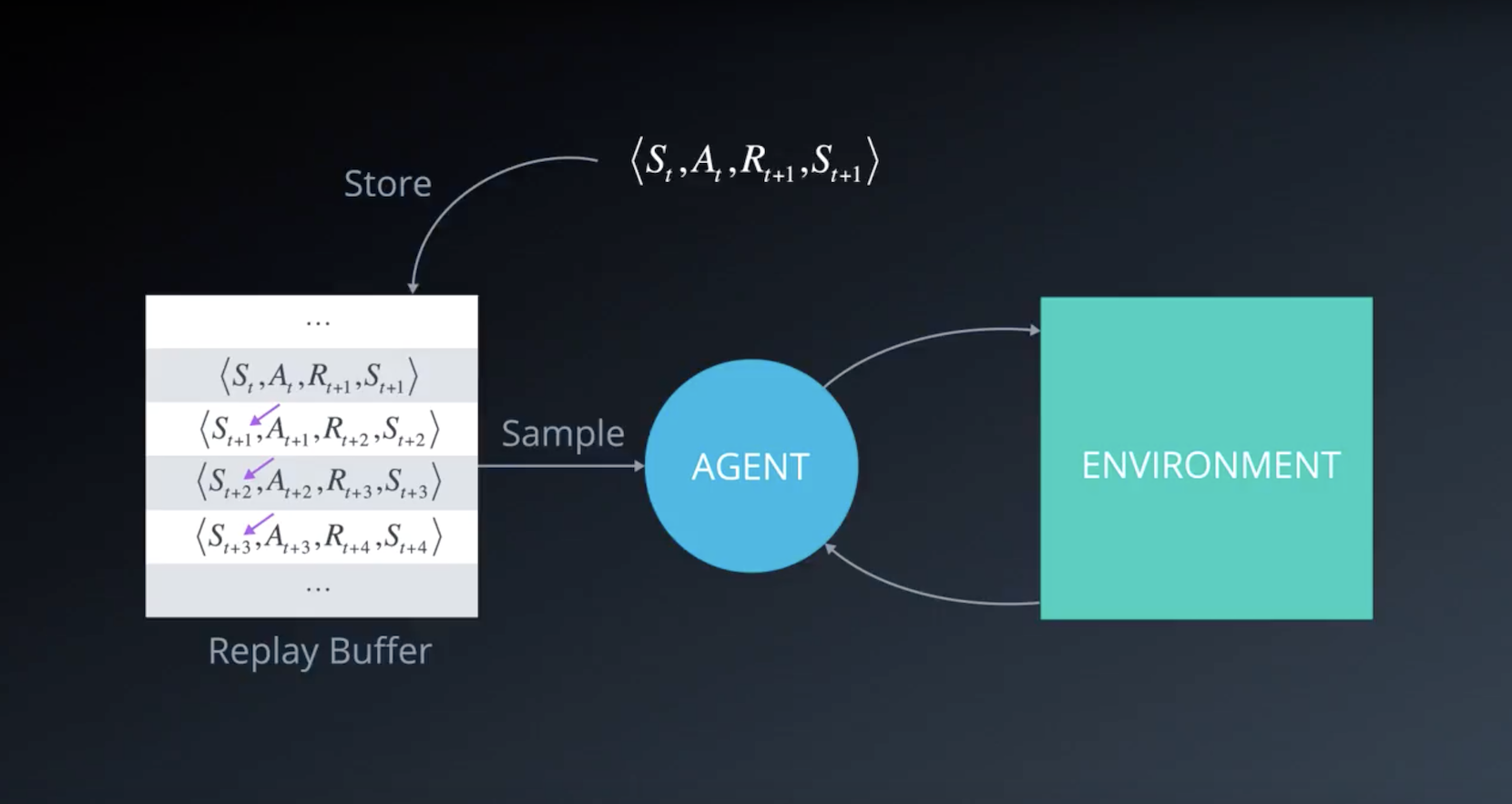
When the agent interacts with the environment, the sequence of experience tuples can be highly correlated. The naive Q-learning algorithm that learns from each of these experience tuples in sequential order runs the risk of getting swayed by the effects of this correlation. By instead keeping track of a replay buffer and using experience replay to sample from the buffer at random, we can prevent action values from oscillating or diverging catastrophically.
The replay buffer contains a collection of experience tuples (S, A, R, S′). The tuples are gradually added to the buffer as we are interacting with the environment.
The act of sampling a small batch of tuples from the replay buffer in order to learn is known as experience replay. In addition to breaking harmful correlations, experience replay allows us to learn more from individual tuples multiple times, recall rare occurrences, and in general make better use of our experience.
Quiz
Which of the following are true? Select all that apply.
- Experience replay is based on the idea that we can learn better, if we do multiple passes over the same experience.
- Experience replay causes harmful correlations and can cause lead to action-value estimates that fail to converge while training.
- Experience replay is used to generate uncorrelated experience data for online training of deep RL agents.
- Once an experience tuple is randomly sampled from the replay buffer, the agent learns from it, and then it is discarded from the buffer.
2-4-4 : Fixed Q-Targets
from IPython.display import Image
Image(filename='./images/2-4-4-1_dqn_fiexed_Q-Targets_step1.png')

from IPython.display import Image
Image(filename='./images/2-4-4-2_dqn_fiexed_Q-Targets_step2.png')

from IPython.display import Image
Image(filename='./images/2-4-4-3_dqn_fiexed_Q-Targets_step3.png')

from IPython.display import Image
Image(filename='./images/2-4-4-4_dqn_fiexed_Q-Targets_step4.png')

from IPython.display import Image
Image(filename='./images/2-4-4-5_dqn_fiexed_Q-Targets_step5.png')

from IPython.display import Image
Image(filename='./images/2-4-4-6_dqn_fiexed_Q-Targets_step6.png')

from IPython.display import Image
Image(filename='./images/2-4-4-7_dqn_fiexed_Q-Targets_step7.png')

from IPython.display import Image
Image(filename='./images/2-4-4-8_dqn_fiexed_Q-Targets_dunkey_example_step1.png')

from IPython.display import Image
Image(filename='./images/2-4-4-9_dqn_fiexed_Q-Targets_dunkey_example_step2.png')

from IPython.display import Image
Image(filename='./images/2-4-4-10_dqn_fiexed_Q-Targets_dunkey_example_step3.png')

from IPython.display import HTML
HTML('<iframe width="560" height="315" src="https://www.youtube.com/embed/-PVFBGN_zoM" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>')
/Users/parksurk/miniconda3/envs/drlnd/lib/python3.6/site-packages/IPython/core/display.py:689: UserWarning: Consider using IPython.display.IFrame instead
warnings.warn("Consider using IPython.display.IFrame instead")
from IPython.display import Image
Image(filename='./images/2-4-4-11_dqn_fiexed_Q-Targets_dunkey_example_step4.png')

from IPython.display import Image
Image(filename='./images/2-4-4-12_dqn_fiexed_Q-Targets_dunkey_example_step5.png')

from IPython.display import Image
Image(filename='./images/2-4-4-13_dqn_fiexed_Q-Targets_dunkey_example_step6.png')

from IPython.display import Image
Image(filename='./images/2-4-4-14_dqn_fiexed_Q-Targets.png')

from IPython.display import Image
Image(filename='./images/2-4-4-15_dqn_fiexed_Q-Targets_decoupled.png')

Summary of Fixed Q-Targets
In Q-Learning, we update a guess with a guess, and this can potentially lead to harmful correlations. To avoid this, we can update the parameters w in the network q^ to better approximate the action value corresponding to state S and action A with the following update rule:
from IPython.display import Image
Image(filename='./images/2-4-4-16_dqn_fiexed_Q-Targets_equation.png')

where w− are the weights of a separate target network that are not changed during the learning step, and (S, A, R, S′) is an experience tuple.
Quiz
Which of the following are true? Select all that apply.
- The Deep Q-Learning algorithm uses two separate networks with identical architectures.
- The Deep Q-Learning algorithm uses two separate networks with different architectures.
- Every time we update the primary Q-Network, we immediately update the target Q-Network weights, so that they match after each learning step.
- The target Q-Network’s weights are updated less often (or more slowly) than the primary Q-Network.
- Without fixed Q-targets, we would encounter a harmful form of correlation, whereby we shift the parameters of the network based on a constantly moving target.
2-4-5 :Deep Q-Learning Algorithm
Please take the time now to read the research paper that introduces the Deep Q-Learning algorithm.).
from IPython.display import Image
Image(filename='./images/2-4-5-1_dqn_algorithm_step1.png')

from IPython.display import Image
Image(filename='./images/2-4-5-2_dqn_algorithm_step2.png')

from IPython.display import Image
Image(filename='./images/2-4-5-3_dqn_algorithm_step3.png')

from IPython.display import Image
Image(filename='./images/2-4-5-4_dqn_algorithm_step4.png')

from IPython.display import Image
Image(filename='./images/2-4-5-5_dqn_algorithm_step5.png')

from IPython.display import Image
Image(filename='./images/2-4-5-6_dqn_algorithm_step6.png')

from IPython.display import Image
Image(filename='./images/2-4-5-7_dqn_algorithm_step7.png')

for each episode and each time step t within that episode you observe a raw screen image or input frame Xt which you need to convert to grayscale crop to a square size, etc.. Also, in order to capture temporal relationships you can stack a few input frames to build each state vector.
Let’s denote this pre-processing and stacking operation by the function phi, which takes a sequence of frames and produces some combined representation.
Note that if we want to stack say four frames will have to do something special for the first, three time steps. For instance, we can treat those missing frames as blank, or just used copies of the first frame, or we can just skip storing the experience tuples till we get a complete sequence.
In practice, you won’t be able to run the learning step immediately. You will need to wait till you have sufficient number of tuples in memory.
Note that we do not clear out the memory after each episode, this enables us to recall and build batches of experiences from across episodes.
There are many other techniques and optimizations that are used in the DQN paper, such as
- reward clipping
- error clipping
- storing past actions as part of the state vector
- dealing with terminal states
- digging epsilon over time
- et cetera.
2-4-6 :Deep Q-Learning Improvements
Several improvements to the original Deep Q-Learning algorithm have been suggested. Over the next several lessons, we’ll look at three of the more prominent ones.
Double DQN
Deep Q-Learning tends to overestimate ( refer to “Issues in Using Function Approximation for Reinforcement Learning” paper) action values. Double Q-Learning ( refer to “Deep Reinforcement Learning with Double Q-learning” paper) has been shown to work well in practice to help with this.
Prioritized Experience Replay
Deep Q-Learning samples experience transitions uniformly from a replay memory. Prioritized experienced replay (refer to “Prioritized experienced replay” paper) is based on the idea that the agent can learn more effectively from some transitions than from others, and the more important transitions should be sampled with higher probability.
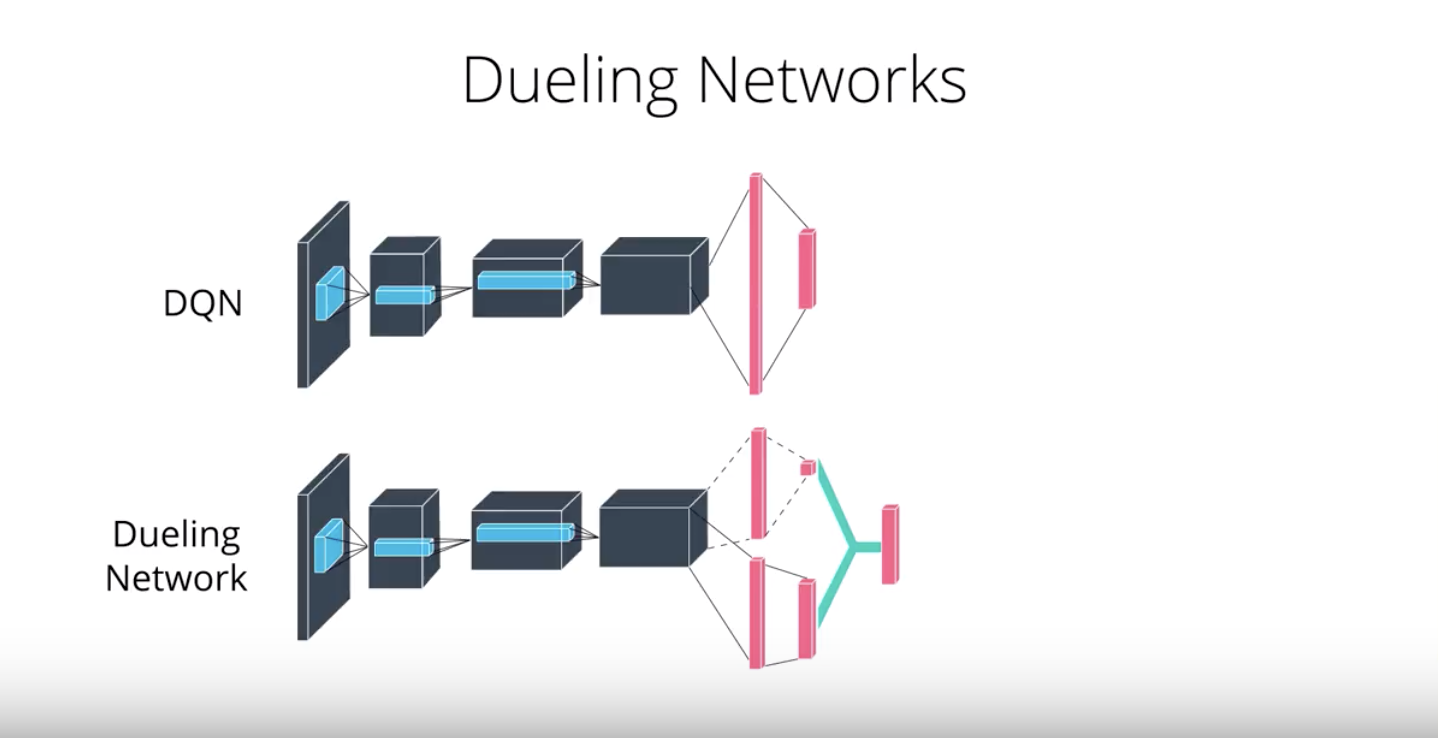
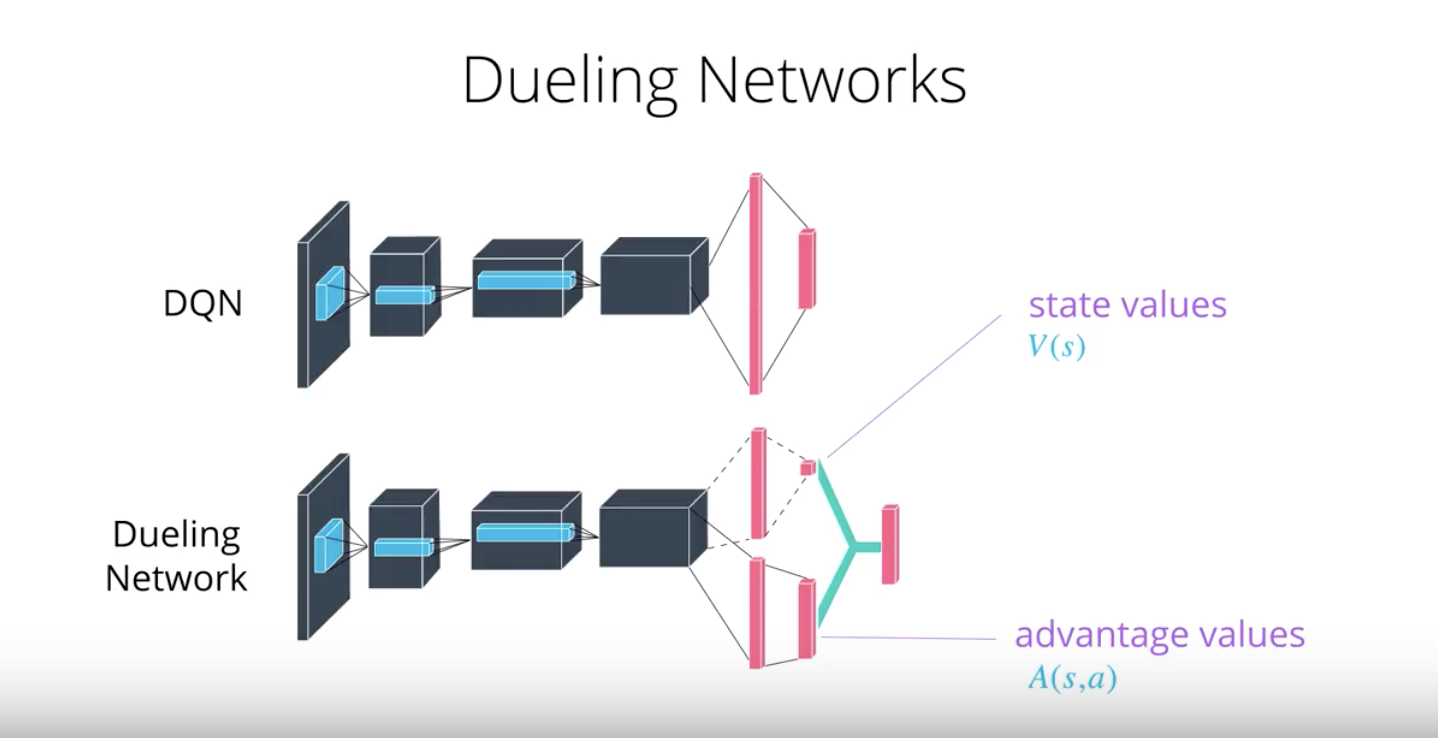
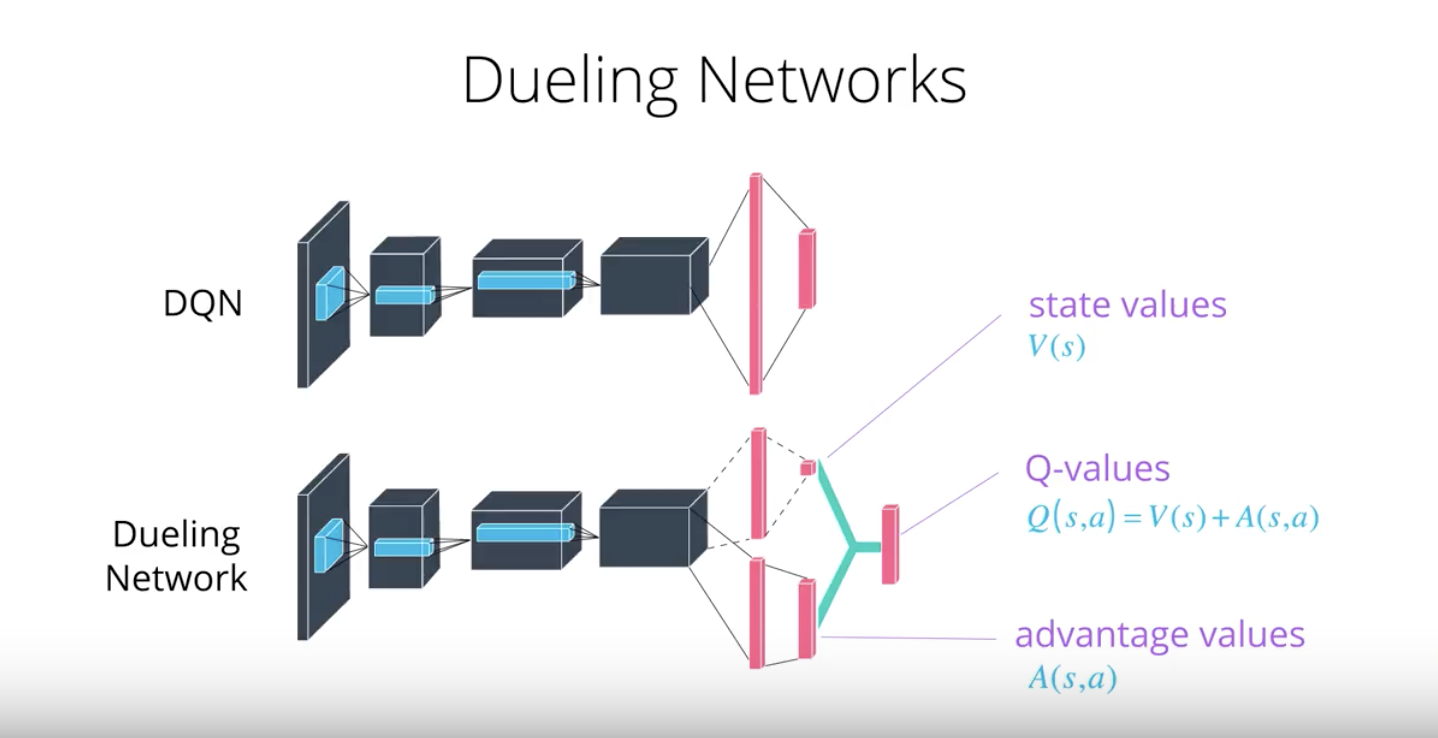
Dueling DQN
Currently, in order to determine which states are (or are not) valuable, we have to estimate the corresponding action values for each action. However, by replacing the traditional Deep Q-Network (DQN) architecture with a dueling architecture (refer to “Dueling Network Architectures for Deep Reinforcement Learning” paper), we can assess the value of each state, without having to learn the effect of each action.
2-4-7 :Double DQN
You can read more about Double DQN (DDQN) by perusing this research paper.
If you’d like to dig deeper into how Deep Q-Learning overestimates action values, please read this research paper.
from IPython.display import Image
Image(filename='./images/2-4-7-1_Double-DQN.png')

from IPython.display import Image
Image(filename='./images/2-4-7-2_Double-DQN.png')

from IPython.display import Image
Image(filename='./images/2-4-7-3_Double-DQN.png')

from IPython.display import Image
Image(filename='./images/2-4-7-4_Double-DQN.png')

2-4-8 :Prioritized Experience Replay
You can read more about prioritized experience replay by perusing this research paper.
from IPython.display import Image
Image(filename='./images/2-4-8-1_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-2_PER.png')
from IPython.display import Image
Image(filename='./images/2-4-8-3_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-4_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-5_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-6_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-7_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-8_PER.png')

from IPython.display import Image
Image(filename='./images/2-4-8-9_PER.png')

2-4-9 :Dueling DQN
You can read more about Dueling DQN by perusing this research paper.
from IPython.display import Image
Image(filename='./images/2-4-9-1_Dueling-DQN.png')
from IPython.display import Image
Image(filename='./images/2-4-9-2_Dueling-DQN.png')
from IPython.display import Image
Image(filename='./images/2-4-9-3_Dueling-DQN.png')
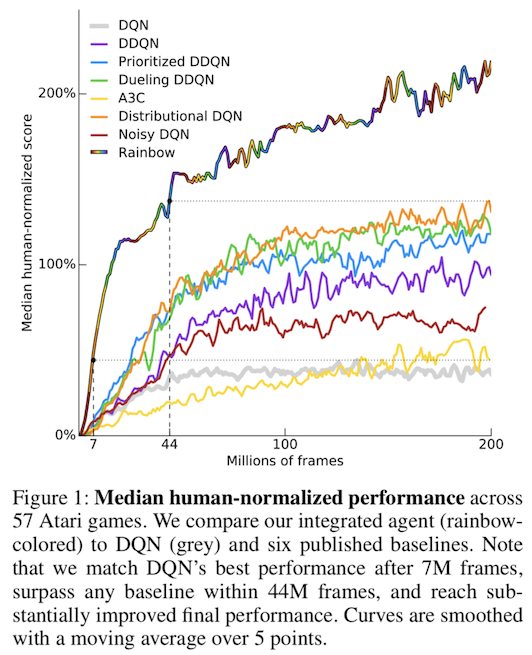
2-4-10 :Rainbow
So far, you’ve learned about three extensions to the Deep Q-Networks (DQN) algorithm:
- Double DQN (DDQN)
- Prioritized experience replay
- Dueling DQN
But these aren’t the only extensions to the DQN algorithm! Many more extensions have been proposed, including:
- Learning from multi-step bootstrap targets (as in A3C - you’ll learn about this in Policy-based Method)
- Distributional DQN
- Noisy DQN
Each of the six extensions address a different issue with the original DQN algorithm.
Researchers at Google DeepMind recently tested the performance of an agent that incorporated all six of these modifications. The corresponding algorithm was termed Rainbow.
It outperforms each of the individual modifications and achieves state-of-the-art performance on Atari 2600 games!
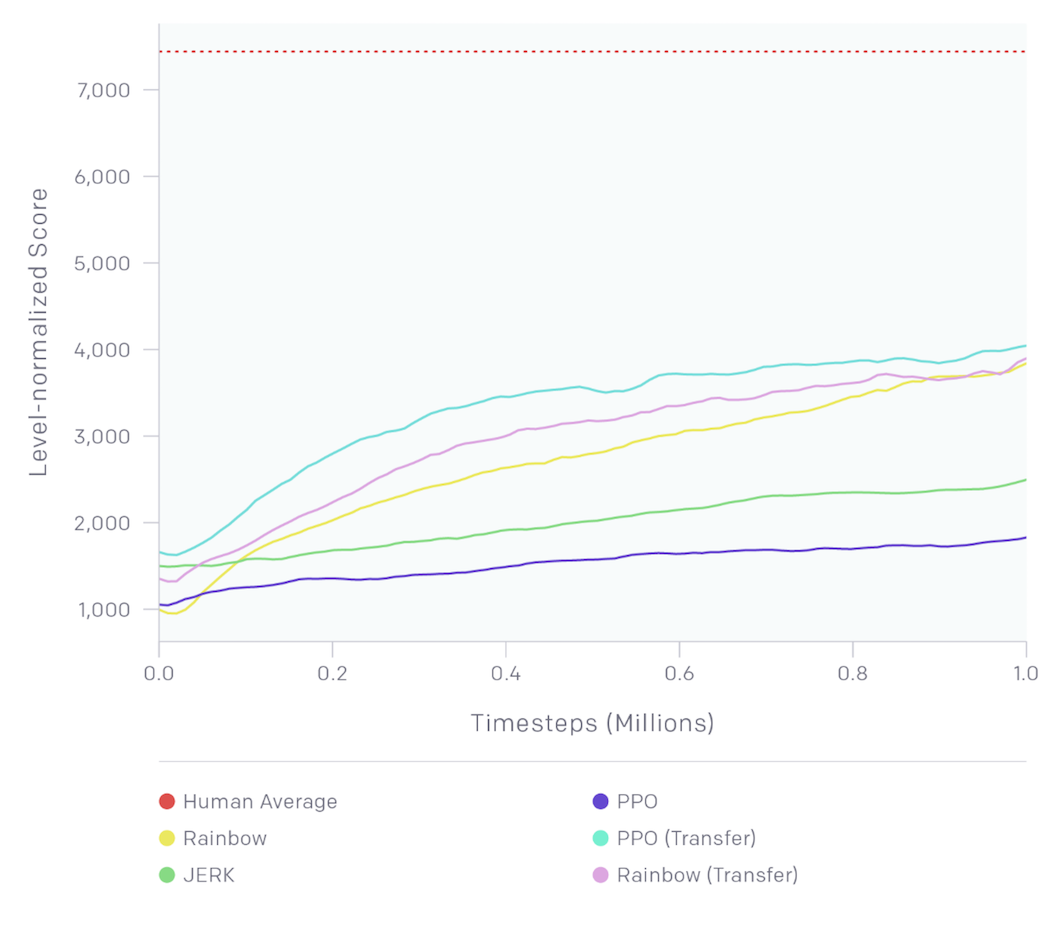
In Practice
In mid-2018, OpenAI held a contest, where participants were tasked to create an algorithm that could learn to play the Sonic the Hedgehog game. The participants were tasked to train their RL algorithms on provided game levels; then, the trained agents were ranked according to their performance on previously unseen levels.
Thus, the contest was designed to assess the ability of trained RL agents to generalize to new tasks.

One of the provided baseline algorithms was Rainbow DQN.
If you’d like to play with this dataset and run the baseline algorithms, you’re encouraged to follow the setup instructions.
Leave a comment