
Beyond current NLP with HMTL(번역)
Updated:
HMTL로 NLP의 최첨단 기술을 뛰어 넘다.
(Orinial Blog = https://medium.com/huggingface/beating-the-state-of-the-art-in-nlp-with-hmtl-b4e1d5c3faf?fbclid=IwAR32nqSOE2K3HxYZ0pKYSOxgdcE8dD52H8ZZ_9YIzaJQJWX1H6N9FI3EVLc)
HMTL = Hierarchical Multi-Task Learning model
최근 NLP분야가 떠오르면서 다중 작업 학습 (Multi-Task Learning )이라고 불리는 딥러닝 (Deep-Learning) 및 인공 지능 (Artificial Intelligence) 기술이 새롭게 소개되고 있습니다.
저(Victor Sanh)는 거의 1년 동안 Multi-Task Learning을 실험해 왔고 그 결과가 HMTL입니다. HMTL은 여러 가지 NLP 작업에서 최첨단 기술을 능가하는 모델이며 까다로운 논문심사로 유명한 AAAI(Association for the Advancement of Artificial Intelligence) 2019 국제학회에서 발표될 예정입니다. 최근 릴리즈된 논문 과 코드 도 참조 바랍니다.
자 그러면…, Multi-Task Learning이란 무엇일까요?
다중 태스크 학습은 단일 아키텍처가 동시에 여러 가지 태스크를 학습하도록 훈련되는 일반적인 방법입니다.
다음은 예입니다. HMTL을 대화식으로 실행하는 멋진 온라인 데모 를 만들었으니 직접 시도해보세오! 🎮

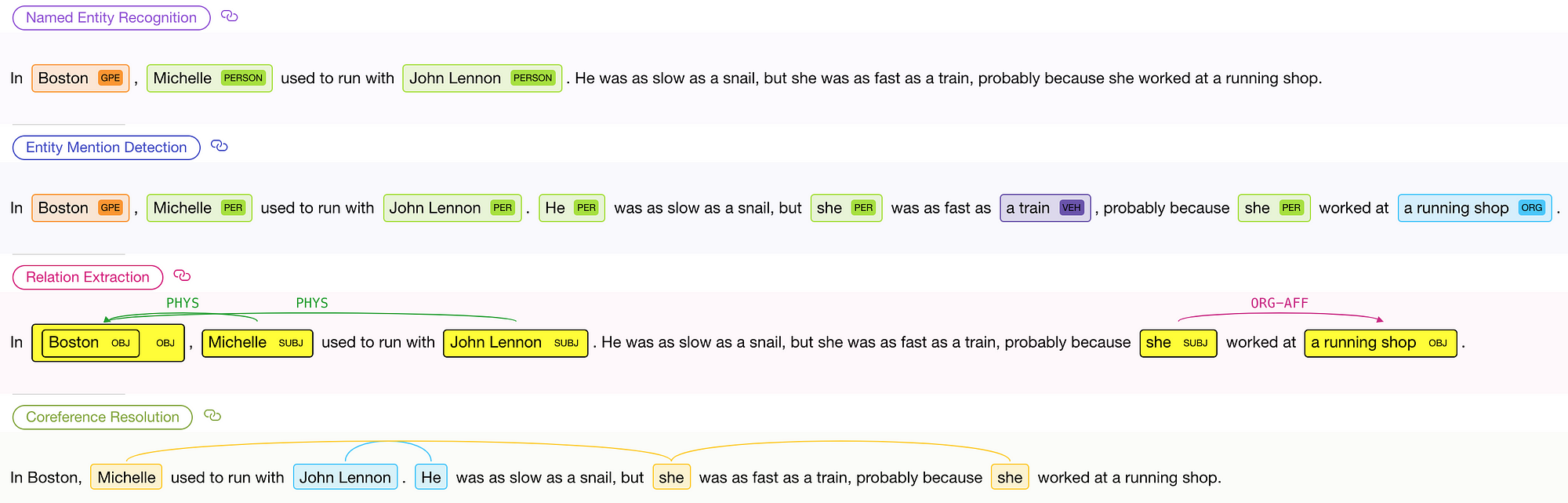
HMTL 온라인 데모 에서 얻은 결과의 예
전통적으로 특정 모델은 이러한 각 NLP 작업 (Named-Entity Recognition, Entity Mention Detection, Relation Extraction, Coreference Resolution)에 대해 독립적으로 학습되었습니다.
HMTL의 경우, 모든 결과가 단일 모델(Single Model) 과 Single Forward Path 로 부터 나옵니다!
그러나 다중 작업 학습은 여러 모델 대신 단일 모델을 사용하여 계산을 줄이는 단순한 방법 이상의 것입니다.
MTL (Multi-Task Learning)을 사용하면 모델이 다른 작업간에도 공유 할 수있는 Embedding을 학습하도록 유도 할 수 있습니다. Multi-Task Learning의 근본적인 Motivation 중 하나는 richer representations 을 유도하여 각 Task들로 무터 나오는 이점(Benefit) 을 모두 가져오겠다는 생각입니다.
이 글에서는 HMTL이 NLP Applications에 대해 얼마나 강력하고 다용도의 다중 작업 학습이 가능한지에 대해 알려 드리려고합니다. 먼저, 다중 작업 학습이 왜 흥미로운 Trend인지에 대한 몇 가지 직관을 공유합니다.
Multi-Task Learning에 대한 간략한 소개와 중요한 이유.
고전적인 기계 학습 Setup시에 Single Task를 최적화하기 위해 Single Loss Function을 최적화하여 단일 모델을 학습합니다. 관심있는 (하나의) 작업에 초점을 맞추는 것이 기계 학습의 많은 문제에 대한 일반적인 접근 방법이지만 다른 관련 (또는 느슨하게 관련된) 작업이 성능을 향상시키기 위해 가져올 수있는 정보는 활용하지 않습니다.

- 출처 : Cheezburger.com
세계 기록 (2018.11 현재) 타이틀 보유자 인 우사인 볼트 (Usain Bolt, 1919 출생, 올림픽 금메달리스트 🥇) 사례를 살펴봅시다. 실제로 우사인의 경우 훈련시 가장 중요한 부분은 달리기(Running)이 아니라 다른 운동들입니다. 예를 들어, weights, box jumps, bounds 등 입니다.이 운동들은 달리기와 직접적인 관련이 없지만 궁극적인 목표 인 단거리달리기(Sprint)에서 자신의 근력과 폭발력을 향상시킵니다.
“다중 작업 학습은 관련 작업의 학습 Signal에 포함된 도메인 정보를 Inductive Bias으로 사용하여 Generalization를 향상시키는 Inductive Transfer하기 위한 하나의 접근 방법입니다. Shared Representation을 사용하면서 병렬로 작업을 학습하여 이를 수행합니다. 각 과제에 대해 배운 것이 다른 과제를 더 잘 학습하는 데 도움이 될 수 있습니다. “R. Caruana 참조1
Natural Language Processing에서 MTL은 R. Collobert와 J. Weston 참조2 의 신경 기반 접근 방식에서 처음으로 활용되었습니다. 그들이 제안한 모델은 여러 작업 (작업 별 레이어 포함) 이 서로 다른 작업의 Supervised-Leaning에 의해 훈련 된 동일한 공유 임베딩(Shared Embedding) 에 의존하는 MTL 인스턴스입니다.
서로 다른 작업간에 동일한 Representation을 공유하는 것은 한 가지 작업에서 다른 작업 으로 관련 지식을 전달 하는 아주 낮은 수준의 신호 / 방법처럼 들릴 수 있지만 모델의 일반화 능력을 향상시킬 수있는 능력에 특히 유용하다는 것이 입증되었습니다.
정보가 태스크간에 전송되는 방법을 미리 고치는 것은 일반적이며 직접적으로 이루어 지지만 주어진 태스크에 가장 적합한 계층과 함께 공유 할 매개 변수와 계층을 모델 자체에서 결정하게 할 수도 있습니다 Ruder et al., 2017 참조3.
최근에, 이러한 공유된 표현(Shared Represetation)에 대한 아이디어는 영역 전반에 걸쳐 사용될 수 있고 특정 태스크 만의 것이 아닌 “Universal Sentence Embeddings“를 통해 다시 주목 받고 있습니다 (Conneau 등 참조4 ). 몇 가지 시도들이 MTL에 의존하고 있는데… 예를 들어, Subramanian et al. 참조5 은 다양한 작업에 걸쳐 일반화 할 수있음을 연구하였는데, 이 일반화는 문장의 다중 언어 양상(multiple linguistic aspect)을 인코딩하는 것이 필요하다고 주장하고 Gensen 을 제안했는데 이는 공유된 인코더 표현(Shared Encoder Represetation)과 몇 가지 작업별 레이어가 뒤따르는 MTL 아키텍처를 제안했습니다. 이 작업에서 사용 된 6 가지 작업은 서로 관련이 느슨한 테스크인 ‘Natural Language Inference’ 에서 부터 ‘Machine Translation through Constituency Parsing’ 까지의 다양한 범위에 이릅니다.
이에 대한 자세한 내용은 다음 블로그를 참고하십시요. blog post on Universal Word and Sentence Embeddings📚
요컨대, 다중 작업 학습은 많은 관심을 끌고 있으며 NLP의 다양한 문제에 대해 적용시 반드시 알아야 할 내용입니다. 이는 또한 Computer Vision 👀 영역에 대해에서도 마찬입니다. GLUE 벤치 마크 (General Language Understanding Evaluation, Wang et al. 참조6 ) 와 같은 벤치 마크 는 최근에 MTL 아키텍처의 일반화 능력과 Language Understanding 모델을 평가하기 위해 소개되었습니다.
NLP에서 MTL에 대한보다 포괄적 인 개요를 보려면 S. Ruder의 [블로그 포스트][] 를 참조하십시오.📚
파이썬에서 다중 작업 학습 🐍
🔥 이제 MTL이 실제로 어떻게 보이는지 몇 가지 코드를 보도록 하겠습니다.
Multi-Task Learning Scheme의 매우 중요한 부분은 트레이너(Trainer) 입니다. : 네트워크를 어떻게 Train해야합니까? 여러 가지 테스크를 어느 순서로 수행해야 하나요? 주기적으로 테스크를 스위칭해야 하나요? 같은 수의 Epoch를 써야 하나요? 현재까지는 모든 질문에 대한 명확한 합의가 없으며, 많은 서로다른 Train 절차가 다양한 문헌에서 제안되었습니다.
먼저, 우리가 선택하는 Train 과정에 맞는 간단하고 일반적인 코드로 시작해 보겠습니다.
- Select a task (선택한 알고리즘이 무엇이든 상관없습니다).
- Select a batch(일반적으로 Random하게 배치를 샘플링하는 것이 안전한 선택입니다).
- Perform a forward pass
- Propagate the loss (backward pass = Back Propagation)
이 4 단계는 대부분의 경우에 적합해야합니다.
forward pass 중에 모델은 해당 테스크의 loss을 계산합니다. backward pass 동안 loss로부터 계산된 Gradient는 네트워크를 통해 전파되어 테스크 특정 layer과 공유된 임베딩(및 기타 모든 관련된 학습 가능 매개 변수)을 최적화합니다.
Hugging Face 챗봇 사이트에서, ‘Allen Institute for AI’에서 개발한 AllenNLP에 라이브러리를 사용합니다. AllenNLP에 라이브러리는 NLP에서 데이터로드 및 처리를 위해 PyTorch의 유연성과 스마트한 모듈을 제공하여 NLP의 연구를 수행할 때 강력하고 다양한 도구로 사용할 수 있습니다.
이에 대해서 자세한 내용을 원하시면 AllenNLP 온보드 자습서 를 참고하십시요. 😬
이제 AllenNLP에 기반한 MTL 트레이너를 작성하기위한 간단한 코드을 보여 드리겠습니다.
먼저 테스크 고유의 데이터 세트와 테스크와 직접적으로 관련된 모든 속성을 포함 할 클래스 Task를 소개합니다.
from allennlp.data.iterators import DataIterator
class Task():
"""
A class to encapsulate the necessary informations (and datasets)
about each task.
Parameters
----------
name : ``str``, required
The name of the task.
validation_metric_name : ``str``, required
The name of the validation metric to use to monitor training
to select the best epoch and to stop the training based on exit condition.
validation_metric_decreases : ``bool``, required
Whether or not the validation metric should decrease for improvement.
evaluate_on_test : ``bool`, optional (default = False)
Whether or not the task should be evaluated on the test set at the end of the training.
"""
def __init__(self,
name: str,
validation_metric_name: str,
validation_metric_decreases: bool,
evaluate_on_test: bool = False) -> None:
self._name = name
self._train_data = None
self._validation_data = None
self._test_data = None
self._evaluate_on_test = evaluate_on_test
self._val_metric = validation_metric_name
self._val_metric_decreases = validation_metric_decreases
self._data_iterator = None
def load_data(self,
dataset_path: str,
dataset_type: str):
"""
Load a dataset from a file and store it.
Parameters
----------
dataset_path: ``str``, required
The path to the dataset.
dataset_type: ``str``, required
The type of the dataset (train, validation, test)
"""
assert dataset_type in ["train", "validation", "test"]
dataset = read(dataset_path) # Replace with whatever loading you want.
setattr(self, "_%s_data" % dataset_type, dataset)
def set_data_iterator(self,
data_iterator: DataIterator):
self._data_iterator = data_iterator
이제 클래스 Task가 있으므로 모델을 정의 할 수 있습니다.
AllenNLP에서 모델을 만드는 것은 매우 쉽습니다. allennlp.models.model.Model 클래스에서 상속 받도록하십시오. Train 단계에서 penalties (e.g. L1 or L2 regularizations) 를 적용하는 get_regularization_penalty()와 같은 유용한 Method가 많이 제공 됩니다.
이제 우리가 필요로하는 두 가지 방법에 대해 이야기해 보도록 하겠습니다. forward()및 get_metrics(). 이 방법은 각각 Train 중 현재 작업에 대한 forward pass (up to the loss computation) 및 training/evaluation metrics을 계산합니다.
Multi-task Learning을 위한 중요한 요소는 task_name 라는 특정 인수를 추가하는 것입니다. 코드를 살펴보도록 하겠습니다.
import torch
from allennlp.models.model import Model
class MyMTLModel(Model):
def __init__(self):
"""
Whatever you need to initialize your MTL model/architecture.
"""
def forward(self,
task_name: str,
tensor_batch: torch.Tensor):
"""
Defines the forward pass of the model. This function is designed
to compute a loss function defined by the user.
It should return
Parameters
----------
task_name: ``str``, required
The name of the task for which to compute the forward pass.
tensor_batch: ``torch.Tensor``, required
An embedding representation of the input to pass through the model.
Returns
-------
output_dict: ``Dict[str, torch.Tensor]``
An output dictionary containing at least the computed loss for the task of interest.
"""
raise NotImplementedError
def get_metrics(self,
task_name: str):
"""
Compute and update the metrics for the current task of interest.
Parameters
----------
task_name: ``str``, required
The name of the current task of interest.
Returns
-------
A dictionary of metrics.
"""
raise NotImplementedError
MTL에서 중요한 것은 training task 순서를 선택하는 것이라고 말했습니다. 이는 task를 선택할 때, 각 parameter update(forward + backward passes) 후 균일하게 샘플링하는 작업을 선택하도록하는 가장 직접적인 방법입니다. 이 알고리즘은 앞서 언급 한 Gensen 과 같은 몇 가지 이전 연구에서 사용되었습니다.
여기서 더 좋은 점은…태스크를 선택할 확률이 전체 배치 수에 비해 태스크에 대한 학습 배치의 비율에 비례하는 분포를 따라 임의로 태스크를 선택합니다. 이 샘플링 절차는 나중에 알 수 있듯이 매우 유용하며 ‘catastrophic forgetting’을 방지하기위한 매우 멋진 방법 입니다.
다음 코드는 방금 설명한 절차를 구현합니다. task_list는 Task 목록을 나타냅니다.
from typing import List
import numpy as np
from allennlp.data.iterators import DataIterator
"""
Set the Data Iterator for each task
The data iterator is responsible for yield batches over the specified dataset.
"""
for task in task_list:
task_name = task._name
task.set_data_iterator(DataIterator())
"""
Set whatever DataIterator you like.
Create the sampling probability distribution over the tasks
"""
sampling_prob = [task._data_iterator.get_num_batches(task._train_data) for task in task_list]
sampling_prob = sampling_prob / np.sum(sampling_prob)
def choose_task(sampling_prob):
"""
Randomly choose one task to train.
"""
return np.argmax(np.random.multinomial(1, sampling_prob))
MTL 트레이너를 사용해 봅시다.
다음 코드는 지금까지 구축 한 기본 요소들을 어떻게 조합 할 수 있는지 보여줍니다.
이 train()방법은 작업에 대한 확률 분포에 따라 작업을 반복하고 업데이트 후 MTL 모델 업데이트의 매개 변수를 최적화합니다.
from allennlp.training.optimizers import Optimizer
class MultiTaskTrainer():
def __init__(self,
model: Model,
task_list: List[Task])
self._model = model
self._task_list = task_list
self._optimizers = {}
for task in self._task_list:
self._optimizers[task._name] = Optimizer() # Set the Optimizer you like.
# Each task can have its own optimizer and own learning rate scheduler.
def train(self,
n_epochs: int = 50):
### Instantiate the training generators ###
self._tr_generators = {}
for task in self._task_list:
data_iterator = task._data_iterator
tr_generator = data_iterator(task._train_data,
num_epochs = None)
self._tr_generators[task._name] = tr_generator
### Begin Training ###
self._model.train() # Set the model to train mode.
for i in range(n_epochs):
for _ in range(total_nb_training_batches):
task_idx = choose_task()
task = self._task_list[task_idx]
task_name = task._name
next_batch = next(self._tr_generators[task._name]) # Sample the next batch for the current task of interest.
optimizer = self._optimizers[task._name] # Get the task-specific optimizer for the current task of interest.
optimizer.zero_grad()
output_dict = self._model.forward(task_name = task_name,
tensor_batch = batch) #Forward Pass
loss = output_dict["loss"]
loss.backward() # Backward Pass
validation metrics (cf _val_metric와 _val_metric_decreases in 클래스 Task)을 기반으로하는 Train에 stopping condition을 포함시키는 것은 항상 좋습니다. 예를 들어 validation metrics가 patience number epoch 동안 개선되지 않으면 Train을 중단 할 수 있습니다. 이것은 대개 각각의 Train epoch가 종료된 후에 수행됩니다. 저는 아직 완성하지 못한 상태이어서 이전의 코드를 쉽게 수정하여 이러한 개선 사항을 고려하거나 보다 완벽한 코드 살펴볼 계획입니다.
이 블로그 포스트에서는 커버링하지 않았지만… MTL 모델을 Train하는 데 사용할 수있는 많은 기술이 있습니다. 이와 관련된 멏가지 Reference를 소개합니다. :
- Successive regularization MTL 모델을 Train 할 때 발생하는 주요 문제 중 하나는 catastrophic forgetting 입니다. 모델이 갑자기 이전에 배운 작업과 관련된 지식의 일부를 새 작업이 학습할 때 잊어 버리는 것입니다. 이 현상은 여러 작업이 순차적으로 훈련 될 때 특히 반복됩니다. Hashimoto et al. 참조6 이 Successive regularization 를 도입했씁니다. : loss에 대해 L2 패널티를 추가하여 parameter update가 이전 epoch의 parameter에서 너무 멀어지는 것을 방지합니다. 이 부분에서 MTL 트레이너는 parameter update 후 작업을 switch하지 않고 해당 작업에 대해서 전체 Train Dataset을 처리합니다.
- Multi-Task as Question Answering : 최근, McCann et al. 참조7 은 Multi-Task Learning을 수행하기위한 새로운 패러다임을 소개했습니다. 각 작업은 질의 응답 작업으로 재구성되며 단일 통일 모델 ( MQAN ) 작업에서 고려되는 10 가지 다른 작업에 대해 공동으로 훈련됩니다. MQAN은 WikiSQL의 의미 론적 파싱 작업과 같은 몇 가지 작업에서 최첨단 결과를 얻습니다. 보다 일반적으로,이 연구는 단일 과제 학습의 한계와 다중 과제 학습과 전이 학습의 관계에 대해 논의합니다.
의미 론적 과제에서의 최첨단 기술 개선 : HMTL (Hierarchical Multi-Task Learning Model)
이제 training scheme 에 대해 이야기 했으므로 multi-task learning scheme에서 가장 많은 이점을 얻을 수있는 Model 을 어떻게 개발할 수 있을 지에 대해서 이야기 보도록 하겠습니다.
저의 논문 이 AAAI 2019에서 발표 될 예정인데…제가 제안한 방법은 hierarchical way 입니다.
보다 정확하게 말하자면, 우리는 서로 다른 테스크 간의 언어 계층 구조를 반영하기 위해 선택된 semantic tasks 집합 사이 에 계층 구조 를 만듭니다 (Hashimoto et al. 참조6 )
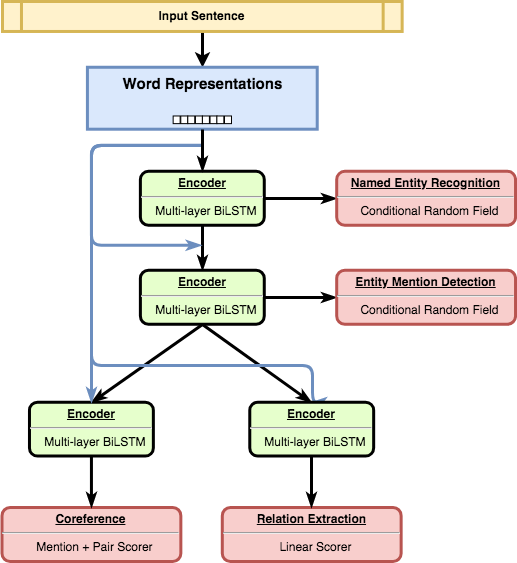
HMTL (계층적 다중 작업 학습) 아키텍처. word representations (embeddings)은 짧은 연결 을 통해 전체 아키텍처에서 공유 됩니다.
그러한 계층 구조의 직관은 일부 작업이 단순 할 수 있고 입력에 대한 제한된 수정이 요구되는 반면 다른 작업은 입력에 대한 지식과 복잡한 처리가 필요할 수 있다는 점입니다.
우리가 고려한 semantic tasks 들은 Named Entity Recognition, Entity Mention Detection, Relation Extraction 및 Coreference Resolution 으로 구성됩니다.
모델은 신경망의 낮은 수준에서 Supervised Learning되는 “더 간단한”작업과 신경망의 상위 계층에서 Supervised Learning되는 “보다 복잡한”작업으로 왼쪽의 그림과 같이 계층 적으로 구성됩니다.
실험에서 우리는 이러한 작업이 다중 작업 학습을 통해 서로 이익을 얻을 수 있음을 관찰했습니다.
- 이 4 가지 작업의 조합은 3 가지 작업 (Named Entity Recognition, Relation Extraction and Entity Mention Detection) 에서 state-of-the-art performance 을 제공합니다.
- MTL framework는 single task training frameworks에 비해 Training Speed 상당히 가속화합니다.
우리는 또한 HMTL에서 학습되어 공유되는 Shared Embeddings 에 대해서도 분석했습니다. 분석을 위해 우리 는 Conneau et al.이 소개 한 10 가지 프로빙 작업인 SentEval 을 사용했습니다. 참조8 . 이러한 프로빙 작업은 sentence embeddings이 다양한 언어 속성(linguistic properties) (통사론, 표면론 및 의미론=syntactic, surface and semantic)을 얼마나 잘 포착 할 수 있는지 평가하는 것을 목표로합니다.
우리의 분석에 따르면 낮은 수준의 Shared Embeddings은 이미 Rich Representation을 인코딩했으며 모델의 아래쪽 레이어에서 상위 레이어로 이동하면 레이어의 숨겨진 상태가 더 복잡한 의미 정보(more complex semantic information) 를 나타내는 경향이 있음을 나타냅니다.
이것으로 다중 태스크 학습에 대한 결론을 마칩니다. 저희가 제안하는 계층 적 모델 (HMTL)에 대해 더 알고 싶다면 논문 📃 및 코드 ⌨️ 를 참고바랍니다.
저희는 괜찮은 온라인 데모 도 만들었습니다. 온라인 데모에서 HMTL을 직접 시험해 볼 수 있습니다! 🎮
참고 문헌
ref1
[1] R. Caruana, Multitask Learning , 1997
ref2
[2] R. Collobert와 J. Weston, A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning , 2008
ref3
3[] , J. Bingel, I. Augenstein and A. Søgaard, Learning what to share between loosely related tasks 2017
ref4
[4] Conneau, D. Kiela, H. Schwenk, L. Barrault와 A. Bordes, Supervised Learning of Universal Sentence Representations from Natural Language Inference Data , 2017
ref5
[5] S, Subramanian, A. Trischler, Y. Bengio와 CJ Pal , 2018 Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
ref6
[6] K.Hashimoto, C. Xiong, Y. Tsuruoka and R. Socher, [JA Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks][] , 2017
ref7
[7] B. McCann, N. S. Keskar, C. Xiong, R. Socher, The Natural Language Decathlon: Multitask Learning as Question Answering 2018
ref8
[8] A. Conneau, D. Kiela, SentEval : An Evaluation Toolkit for Universal Sentence Representations 2018
Leave a comment