
Open Sourcing BERT(번역)
Updated:
Open Sourcing BERT : State-of-the-Art Pre-training for Natural Language Processing
(Orinial Blog = https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html)
Friday, November 2, 2018
Posted by Jacob Devlin and Ming-Wei Chang, Research Scientists, Google AI Language
자연어 처리 (NLP) 의 가장 큰 과제 중 하나는 Training Data가 부족하다는 점입니다. NLP는 자연어처리를 위한 다양한 Task들로 이루어진 분야이므로 대부분의 Task별 Dataset에는 몇 천 개 또는 수십만 개의 human-annotated된 label이 포함되어 있습니다. 최근 Deep Learning기반 NLP 모델인 경우를 보면 Dataset의 크기가 훨씬 큰 수백만 또는 수십억 개의 주석이 달린 Training Example를 학습 할 때, 데이터가 많으면 많을 수록 학습에 유리하게 됨을 확인할 수 있었습니다. 저희는 데이터의 이러한 격차를 줄이기 위해 웹에서 주석이 달린 엄청난 양의 텍스트를 사용하여 General Purpose Language Representation model을 학습하기위한 다양한 기술을 개발했습니다 (이를 pre-training 이라고 함). pre-training 된 모델은 question answering 및 sentiment analysis 과 같은 소규모 데이터 NLP Task에서 fine-tuned 할 수 있으므로 이러한 데이터 세트를 처음부터 교육하는 것과 비교할 때 상당한 정확도 향상을 얻을 수 있습니다. 이번 주, 우리는 Bidirectional Encoder Representations Transformers , 또는 BERT 라는 NLP pre-training을 위한 새로운 기술을 릴리즈 오픈소스로 릴리즈 했습니다. 이 릴리스를 통해 전 세계 누구나 단일 클라우드 TPU 에서 약 30 분 만에 자신의 최첨단 question answering 시스템 (또는 다양한 다른 모델)을 교육 할 수 있습니다. 또한 이 릴리스에는 TensorFlow 와 여러 가지 pre-training 된 언어 표현 모델 위에 구축 된 소스 코드가 포함되어 있습니다. BERT 관련 논문 에서 우리는 매우 경쟁력있는 SQuAD - 스탠포드 question answering 데이터 세트 (SQuAD v1.1)를 포함하여 11 가지의 NLP Task에 대한 최첨단 결과를 보여줍니다 .
BERT의 차별점은 무엇인가요?
BERT는 Semi-supervised Sequence Learning , Generative Pre-Training , ELMo 및 ULMFit을 포함한 pre-training contextual representations에 대한 최근 연구를 밑바탕으로 만들어 졌씁니다. 그러나 이전 모델과 달리 BERT는 최초의 deeply bidirectional, unsupervised language representation 이며, 오직 Wikipedia 에 있는 plain text corpus 만을 사용하여 pre-training 된 language representation 입니다.
왜 이 문제가 중요할까요? pre-trained representations은 문맥 자유형(context-free) 또는 문맥형(contextual) 일 수 있으며, 문맥(cntextual) representation은 단방향(unidirectional) 또는 양방향(bidirectional)일 수 있습니다. word2vec 또는 GloVe 와 같은 문맥없는 모델 은 어휘의 각 단어에 대한 단일 Word Embedding 표현을 생성합니다. 예를 들어, “bank” 라는 단어는 “bank account“와 “bank of the river” 대신 문맥 모델은 문장의 다른 단어를 기반으로하는 각 단어의 표현을 생성합니다. 예를 들어 “ 은행 계좌에 액세스했습니다.(I accessed the bank account) “문장 에서 단방향 문맥 모델은 “ 계정(account) “이 아닌 “ 액세스 한(I accessed the) “을 기반으로 “ 은행(bank) “을 나타냅니다 . 그러나 BERT는 이전 및 다음 컨텍스트 - “I accessed the … account”) - 를 모두 사용하여 “ 은행(bank) “을 나타냅니다. 이는 Deep Neural Network의 맨 아래부터 시작하여 깊게 양방향으로 만들기 때문에 가능합니다.
BERT의 neural network architecture를 이전의 최첨단 contextual pre-training methods과 비교하여 시각화 한 것은 다음과 같습니다. 화살표는 한 레이어에서 다음 레이어로의 정보 흐름을 나타냅니다. 상단의 녹색 상자는 각 입력 단어의 최종 contextualized representation을 나타냅니다.
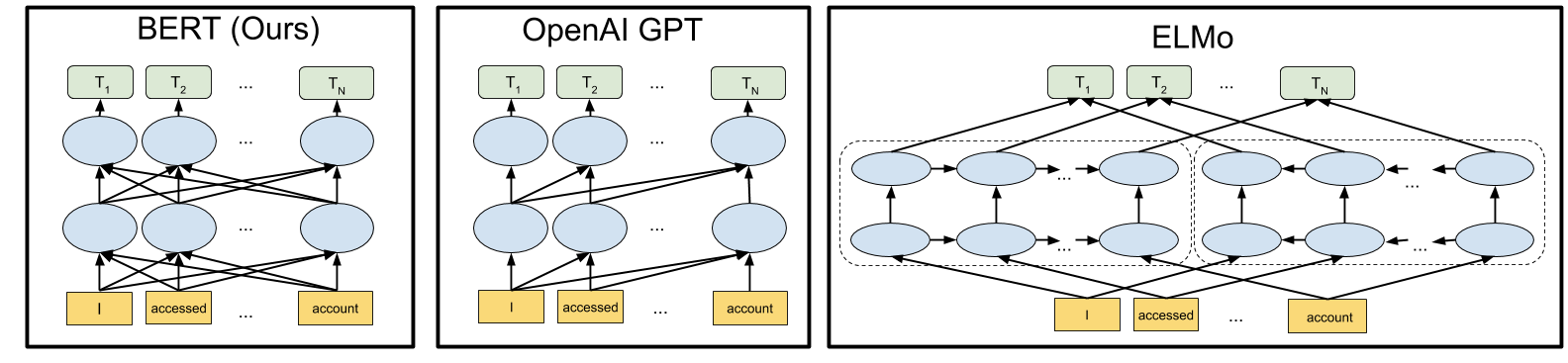
BERT는 양방향이며 OpenAI GPT는 단방향이며 ELMo는 양방향입니다.
양방향성의 강점
양방향성이 너무 강력하다면, 왜 전에는하지 않았을까요? 이유를 이해하려면…먼저 단방향 모델도 문장의 이전 단어를 기반으로 각 단어를 예측하여 효율적으로 학습되고 있었다는 것을 알아야 합니다. 그러나 각 단어를 중심으로 이전 단어와 다음 단어를 단순히 학습 조건으로 고려한다고 해서 양방향 모델을 학습 할 수는 없습니다. 양방향 모델이 예측할 단어가 다층 모델(multi-layer model)에서 간접적으로 “자기 자신을 보는 것(see itself)”를 허용하기 때문입니다.
이 문제를 해결하기 위해 입력의 일부 단어를 마스킹 한 다음 각 단어를 양방향으로 조건 설정하여 마스킹 된 단어를 예측하는 간단한 방법을 사용합니다. 예 :

이 아이디어는 과거에도 매우 오랜 시간 동안 시도되었지만 , BERT가 자연어 처리 영역에서 deep neural network를 pre-training 하여 적용하는 것에 처음으로 성공적으로 사용되었다고 생각합니다.
BERT는 텍스트 말뭉치(Corpus)로부터 생성 될 수있는 매우 간단한 Task를 pre-training하여 문장 사이의 관계를 모델링하것을 배웁니다. : 아래 예를 보시면…A, B 두 문장을 감안할 때, A문장의 다음에 오는 B문장이 ‘실제 다음 분장’일까요…아니면 ‘ 단수히 Random하게 다음에 올수 있는 문장’ 일까요?
예 :

클라우드 TPU로 교육
지금까지 BERT에 대해서 설명한 부분 중 빠진 부분이 있습니다. 바로 BERT가 클라우드 TPU 를 사용한다는 점입니다. 클라우드 TPU를 사용하면 모델을 신속하게 실험, 디버그 및 조정할 수 있으므로 기존의 pre-training 기술을 뛰어 넘는 데 중요한 역할을 했습니다. 2017년 구글 연구진에 의해 개발된 Transformer model architecture 또한 BERT의 성공에 있어서 필요한 기본적인 아키택쳐를 주었습니다. 참고로 Transformer는 BERT release 와 tensor2tensor 라이브러리 에서도 사용됩니다.
BERT 결과
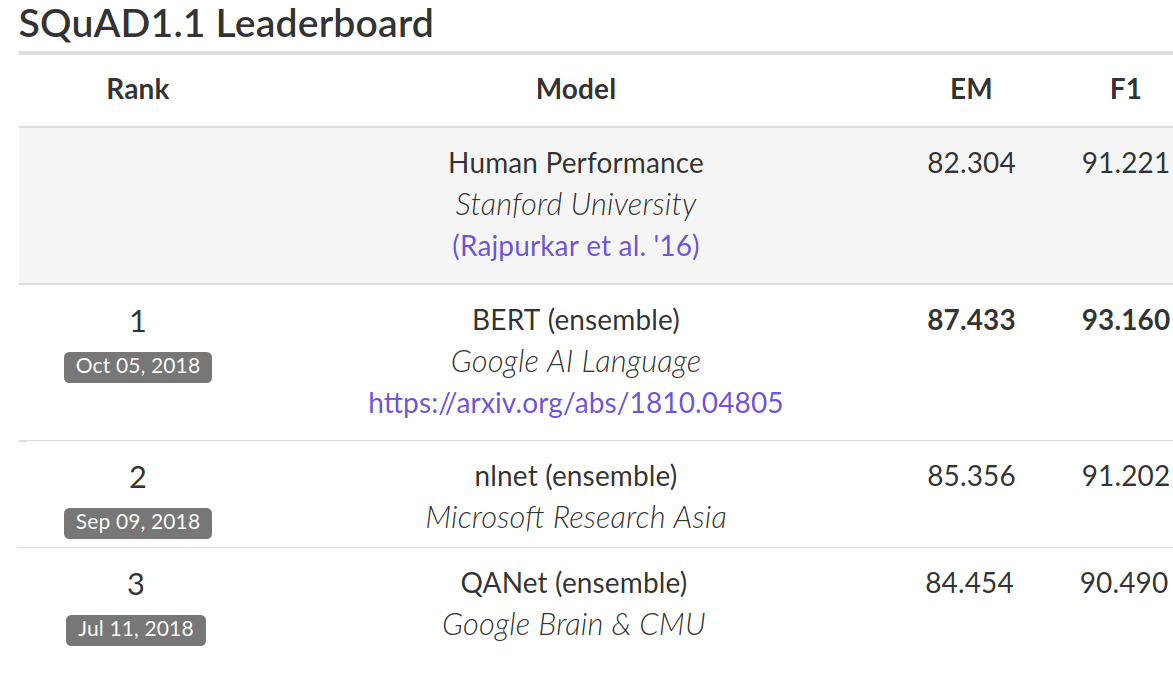
성능을 평가하기 위해 BERT와 다른 최첨단 NLP 시스템을 비교했습니다. BERT는 neural network architecture에 대한 Task 별 변경없이 거의 모든 괄목할 만한 성과를 달성했습니다. SQuAD V1.1 Dataset 에서 BERT는 93.2 %의 F1 점수(정확도의 척도)를 달성함으로써 이전 최고 점수인 91.6 %를 뛰어 넘었으며, 91.2 %의 Human-Level 점수도 능가하였습니다. :
BERT는 또한 매우 까다로운 GLUE 벤치 마크 (9 가지 다양한 NLU-Natural Language Understanding Task 세트)에서 정확도를 7.6 % 향상시킵니다 . 이러한 Task에서 human-labeled training data의 양은 2,500 개에서 400,000 개로 다양하며, BERT 는 그 모두에 대한 GLUE 벤치 마크 정확도를 향상시킵니다 .

BERT 작동시키기
BERT 모델은 몇 시간 이내에 다양한 NLP Task을 미세 조정할 수 있습니다. BERT Release에는 pre-training을 실행하는 코드도 포함되어 있습니다. BERT를 사용하는 대다수의 NLP researcher들이 자신의 모델을 scratch에서 부터 pre-train 할 필요는 없다고 생각합니다. 오늘 발표하는 BERT 모델은 영어 전용이지만, 가까운 미래에 다양한 언어로 사전 교육을받은 모델을 출시하기를 바랍니다.
BERT TensorFlow 구현 및 pre-trained 된 BERT 모델에 대한 지침은 http://goo.gl/language/bert 에서 찾을 수 있습니다. 또는 Jupyter notebook “ BERT FineTuning with Cloud TPUs “ 를 사용하여 Colab 을 통해 BERT를 사용할 수도 있습니다 .
자세한 내용은 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”“을 참조하십시오.

![]()
![]()
레이블 : 딥 학습 , 자연어 처리 , 자연어 이해 , BERT , TensorFlow
Leave a comment